Archive
Giving engineers the freedom to create a customer lock-in Cloud
The Cloud looks like the next dominant platform for hosting applications.
What can a Cloud vendor do to lock customers in to their fluffy part of the sky?
I think that Microsoft showed the way with their network server protocols (in my view this occurred because of the way things evolved, not though any cunning plan for world domination). The EU/Microsoft judgment required Microsoft to document and license their server protocols; the purpose was to allow third-parties to product Microsoft server plug-compatible products. I was an advisor to the Monitoring trustee entrusted with monitoring Microsoft’s compliance and got to spend over a year making sure the documents could be implemented.
Once most the protocol documents were available in a reasonably presentable state (Microsoft originally considered the source code to be the documentation and even offered it to the EU commission to satisfy the documentation requirement; they eventually hire a team of several hundred to produce prose specifications), two very large hurdles to third party implementation became apparent:
- the protocols were a tangled mess of interdependencies; 100% compatibility required implementing all of them (a huge upfront cost),
- the specification of the error behavior (i.e., what happens when something goes wrong) was minimal, e.g., when something unexpected occurs one of the errors in
windows.his returned (when I last checked, 10 years ago, this file contained over 30,000 identifiers).
Third party plugins for Microsoft server protocols are not economically viable (which is why I think Microsoft decided to make the documents public, they had nothing to loose and could claim to be open).
A dominant cloud provider has the benefit of size, they have a huge good-enough code base. A nimbler, smaller, competitor will be looking for ways to attract customers by offering a better service in some area, which means finding a smaller, stand-alone, niche where they can add value. Widespread use of Open Source means everybody gets to see and use most of the code. The way to stop smaller competitors gaining a foothold is to make sure that the code hangs together as a whole, with no relatively stand-alone components that can be easily replaced. Mutual interdependencies and complexity creates a huge barrier to new market entrants and is in the best interests of dominant vendors (yes it creates extra costs for them, but these are the price for detering competitors).
Engineers will create intendependencies between components and think nothing of it; who does not like easy solutions to problems and this one dependency will not hurt will it? Taking the long term view, and stopping engineers taking short cuts for short term gain, requires a lot of effort; who could fault a Cloud vendor for allowing mutual interdependencies and complexity to accumulate over time.
Error handling is a very important topic that rarely gets the attention it deserves, nobody likes to talk about the situation where things go wrong. Error handling is the iceberg of application development, while the code is often very mundane, its sheer volume (it can be 90% of the code in an application) creates a huge lock-in. The circumstances under which a system handles raises an error and the feasible recovery paths are rarely documented in any detail, it is something that developers working at the coal face learn by trial and error.
Any vendor looking to poach customers first needs to make sure they don’t raise any errors that the existing application does not handle and second any errors they do raise need to be solvable using the known recovery paths. Even if there is error handling information available to enable third-parties to duplicate responses, the requirement to duplicate severely hampers any attempt to improve on what already exists (apart from not raising the errors in the first place).
To create an environment for customer lock-in, Cloud vendors need to encourage engineers to keep doing what engineers love to do: adding new features and not worrying about existing spaghetti code.
Ability to remember code improves with experience
What mental abilities separate an expert from a beginner?
In the 1940s de Groot studied expertise in Chess. Players were shown a chess board containing various pieces and then asked to recall the locations of the pieces. When the location of the chess pieces was consistent with a likely game, experts significantly outperformed beginners in correct recall of piece location, but when the pieces were placed at random there was little difference in recall performance between experts and beginners. Also players having the rank of Master were able to reconstruct the positions almost perfectly after viewing the board for just 5 seconds; a recall performance that dropped off sharply with chess ranking.
The interpretation of these results (which have been duplicated in other areas) is that experts have learned how to process and organize information (in their field) as chunks, allowing them to meaningfully structure and interpret board positions; beginners don’t have this ability to organize information and are forced to remember individual pieces.
In 1981 McKeithen, Reitman, Rueter and Hirtle repeated this experiment, but this time using 31 lines of code and programmers of various skill levels. Subjects were given two minutes to study 31 lines of code, followed by three minutes to write (on a blank sheet of paper) all the code they could recall; this process was repeated five times (for the same code). The plot below shows the number of lines correctly recalled by experts (2,000+ hours programming experience), intermediates (just finished programming course) and beginners (just started programming course), left performance using ‘normal’ code and right is performance viewing code created by randomizing lines from ‘normal’ code; only the mean values in each category are available (code+data):
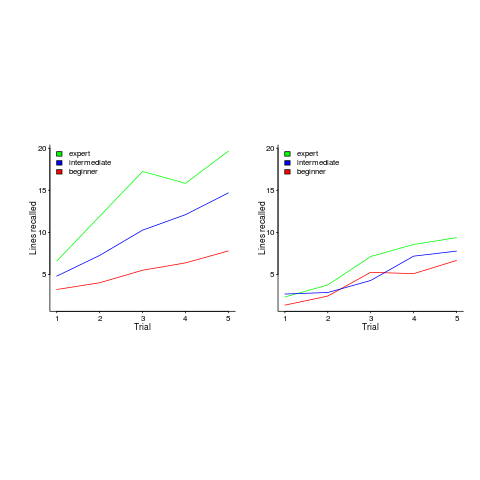
Experts start off remembering more than beginners and their performance improves faster with practice.
Compared to the Power law of practice (where experts should not get a lot better, but beginners should improve a lot), this technique is a much less time consuming way of telling if somebody is an expert or beginner; it also has the advantage of not requiring any application domain knowledge.
If you have 30 minutes to spare, why not test your ‘expertise’ on this code (the .c file, not the .R file that plotted the figure above). It’s 40 odd lines of C from the Linux kernel. I picked C because people who know C++, Java, PHP, etc should have no trouble using existing skills to remember it. What to do:
- You need five blank sheets of paper, a pen, a timer and a way of viewing/not viewing the code,
- view the code for 2 minutes,
- spend 3 minutes writing down what you remember on a clean sheet of paper,
- repeat until done 5 times.
Count how many lines you correctly wrote down for each iteration (let’s not get too fussed about exact indentation when comparing) and send these counts to me (derek at the primary domain used for this blog), plus some basic information on your experience (say years coding in language X, years in Y). It’s anonymous, so don’t include any identifying information.
I will wait a few weeks and then write up the data o this blog, as well as sharing the data.
Update: The first bug in the experiment has been reported. It takes longer than 3 minutes to write out all the code. Options are to stick with the 3 minutes or to spend more time writing. I will leave the choice up to you. In a test situation, maximum time is likely to be fixed, but if you have the time and want to find out how much you remember, go for it.
Power law of practice in software implementation
People get better with practice. The power law of practice specifies  , where:
, where:  is the response time,
is the response time,  the amount of practice and
the amount of practice and  ,
,  and
and  are constants. However, sometimes an exponential equation is a better fit for to the data:
are constants. However, sometimes an exponential equation is a better fit for to the data: } + c") . There are theoretical reasons for liking a power law (e.g., it can be derived from the chunking of information), but it is difficult to argue with the exponential fitting so much data better than a power law.
. There are theoretical reasons for liking a power law (e.g., it can be derived from the chunking of information), but it is difficult to argue with the exponential fitting so much data better than a power law.
The plot below, from a study by Alteneder, shows the time taken to solve the same jig-saw puzzle, for 35 trials (red); followed by a two week pause and another 35 trials (in blue; if anybody else wants to try this, a dedicated weekend should be long enough to complete over 20 trials). The lines are fitted power law and exponential equations (code+data). Can you tell which is which?
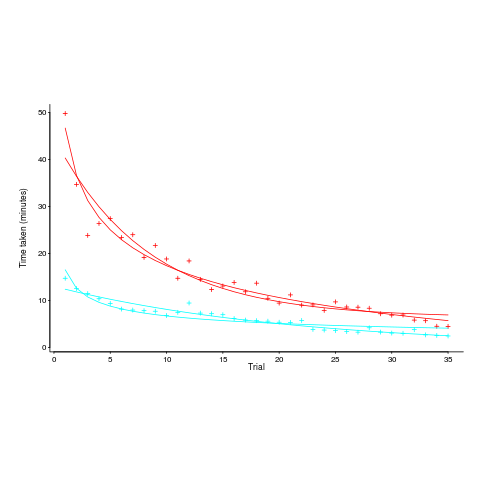
To find out if the same behavior occurs with software we need data on developers implementing the identical applications multiple times. I know of two experiments where the same application has been implemented multiple times by the same people, and where the data is available. Please let me know if you know of any others.
Zislis timed himself implementing 12 algorithms from the CACM collection in each of three languages, iterating four times (my copy came from the Purdue library, which as I write this is not listing the report). The large number of different programs implemented, coupled with the use of multiple languages, makes it difficult to separate out learning effects.
Lui and Chan ran an experiment where 24 developers (8 pairs {pair programming} and 8 singles) implemented the same application four times. The plot below shows the time taken to complete each implementation (singles top, pairs bottom, with black cross showing predictions made by a power law fit).
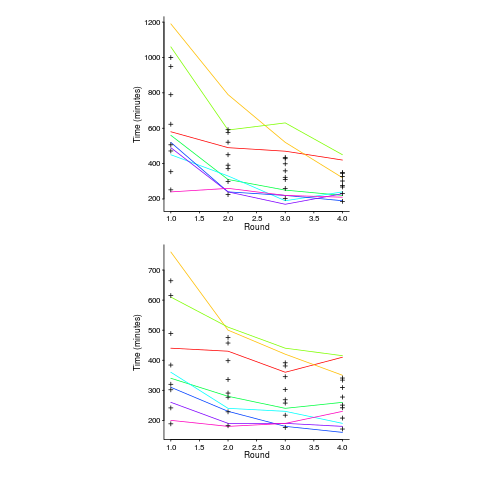
Different subjects start the experiment with different amounts of ability and past experience. Before starting, subjects took a multiple choice test of their knowledge. If we take the results of this test as a proxy for the ability/knowledge at the start of the experiment, then the power law equation becomes (a similar modification can be made to the exponential equation):
^{-b} + c")
That is, the test score is treated as equivalent to performing some number of rounds of implementation). A power law is a better fit than exponential to this data (code+data); the fit captures the general shape, but misses lots of what look like important details.
The experiment was run over successive weekends. So there was opportunity for some forgetting to occur during the week days, and the amount forgotten will vary between people. It is easy to think of other issues that could have influenced subject performance.
This experiment must rank as one of the most interesting software engineering experiments performed to date.
Uncertainty in data causes inconsistent models to be fitted
Does software development benefit from economies of scale, or are there diseconomies of scale?
This question is often expressed using the equation:  . If is less than one there are economies of scale, greater than one there are diseconomies of scale. Why choose this formula? Plotting project effort against project size, using logs scales, produces a series of points that can be sort-of reasonably fitted by a straight line; such a line has the form specified by this equation.
. If is less than one there are economies of scale, greater than one there are diseconomies of scale. Why choose this formula? Plotting project effort against project size, using logs scales, produces a series of points that can be sort-of reasonably fitted by a straight line; such a line has the form specified by this equation.
Over the last 40 years, fitting a collection of points to the above equation has become something of a rite of passage for new researchers in software cost estimation; values for have ranged from 0.6 to 1.5 (not a good sign that things are going to stabilize on an agreed value).
This article is about the analysis of this kind of data, in particular a characteristic of the fitted regression models that has been baffling many researchers; why is it that the model fitted using the equation is not consistent with the model fitted using  , using the same data. Basic algebra requires that the equality
, using the same data. Basic algebra requires that the equality  be true, but in practice there can be large differences.
be true, but in practice there can be large differences.
The data used is Data set B from the paper Software Effort Estimation by Analogy and Regression Toward the Mean (I cannot find a pdf online at the moment; Code+data). Another dataset is COCOMO 81, which I analysed earlier this year (it had this and other problems).
The difference between and  is a result of what most regression modeling algorithms are trying to do; they are trying to minimise an error metric that involves just one variable, the response variable.
is a result of what most regression modeling algorithms are trying to do; they are trying to minimise an error metric that involves just one variable, the response variable.
In the plot below left a straight line regression has been fitted to some Effort/Size data, with all of the error assumed to exist in the  values (dotted red lines show the residual for each data point). The plot on the right is another straight line fit, but this time the error is assumed to be in the
values (dotted red lines show the residual for each data point). The plot on the right is another straight line fit, but this time the error is assumed to be in the  values (dotted green lines show the residual for each data point, with red line from the left plot drawn for reference). Effort is measured in hours and Size in function points, both scales show the
values (dotted green lines show the residual for each data point, with red line from the left plot drawn for reference). Effort is measured in hours and Size in function points, both scales show the  of the actual value.
of the actual value.
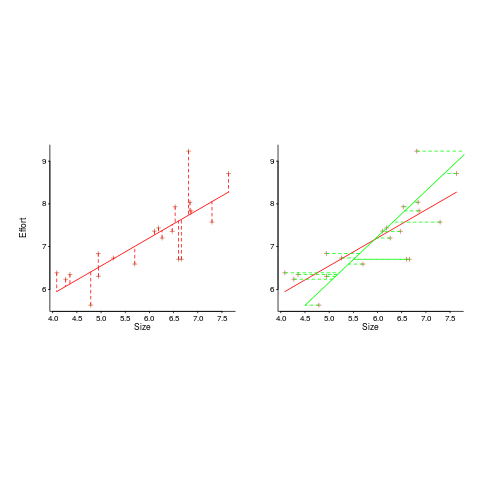
Regression works by assuming that there is NO uncertainty/error in the explanatory variable(s), it is ALL assumed to exist in the response variable. Depending on which variable fills which role, slightly different lines are fitted (or in this case noticeably different lines).
Does this technical stuff really make a difference? If the measurement points are close to the fitted line (like this case), the difference is small enough to ignore. But when measurements are more scattered, the difference may be too large to ignore. In the above case, one fitted model says there are economies of scale (i.e.,  ) and the other model says the opposite (i.e.,
) and the other model says the opposite (i.e.,  , diseconomies of scale).
, diseconomies of scale).
There are several ways of resolving this inconsistency:
- conclude that the data contains too much noise to sensibly fit a a straight line model (I think that after removing a couple of influential observations, a quadratic equation might do a reasonable job; I know this goes against 40 years of existing practice of do what everybody else does…),
- obtain information about other important project characteristics and fit a more sophisticated model (characteristics of one kind or another are causing the variation seen in the measurements). At the moment information is being used to explain all of the variance in the data, which cannot be done in a consistent way,
- fit a model that supports uncertainty/error in all variables. For these measurements there is uncertainty/error in both and ; writing the same software using the same group of people is likely to have produced slightly different Effort/Size values.
There are regression modeling techniques that assume there is uncertainty/error in all variables. These are straight forward to use when all variables are measured using the same units (e.g., miles, kilogram, etc), but otherwise require the user to figure out and specify to the model building process how much uncertainty/error to attribute to each variable.
In my Empirical Software Engineering book I recommend using simex. This package has the advantage that regression models can be built using existing techniques and then ‘retrofitted’ with a given amount of standard deviation in specific explanatory variables. In the code+data for this problem I assumed 10% measurement uncertainty, a number picked out of thin air to sound plausible (its impact is to fit a line midway between the two extremes seen in the right plot above).
Recent Comments