Software engineering data sets
The pretty pictures from my empirical software engineering book are now online, along with the 210 data sets and R code (330M).
Plotting the number of data sets in each year shows that empirical software engineering has really taken off in the last 10 years (code+data). Around dozen or so confidential data sets are not included; I am only writing about data that can be made public.
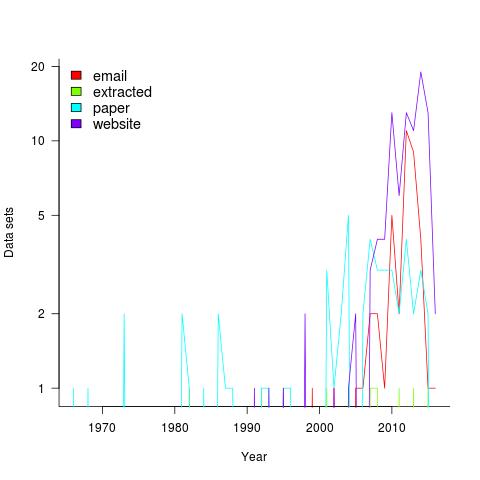
It used to be rare to find the data associated with a paper on the author’s website. Of course, before around 1995 there was no web, but since around 2012 the idea has started to take off.
Contact via email goes back to 1985 and before that people sent mag tapes through the post and many years ago somebody sent me punched tape (there is nothing like seeing the bits with the naked eye).
I have sent several hundred emails asking for data and received 55 data sets. I’m hoping this release will spur those who have promised me data to invest some time to send it.
My experience is that research data often lives on laptops and dies when the laptop is replaced (a study of biologists, who have been collecting data for hundreds of years, found a data ‘death rate’ of 17% a year). Had I started actively collecting data before 2010 the red line in the plot would be much higher for earlier years; I often received data from authors when writing my C book at the start of the century (Google went from nothing to being the best place to search, while I wrote).
In nine cases I extracted the data, either from the pdf or an image and then reverse engineered values.
I have around 50 data sets waiting to be processed. Given that lots more are bound to arrive before the book is finished, I expect to easily reach the 300 mark. A tiny number given my aim of writing about all software engineering issues for which public data exists.
If you know of interesting software engineering data, that is not to be found in these plots, please let me know.
Recent Comments