Archive
Fortran & Cobol in the USAF over the years 1955-1986
I recently discovered a new dataset from Rome’s golden age, going back to 1955. Who knew that in 1955 the US Air Force took delivery of 133,075 lines of Cobol? The plot below shows lines of code against year, broken down by major languages used.
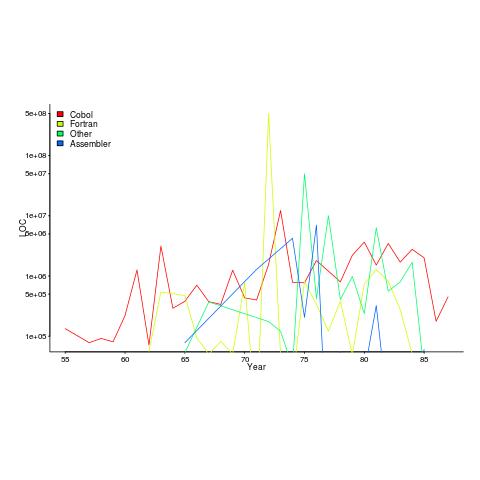
I got the data from the Master’s thesis of Captain NeSmith II (there is probably more software engineering data to be found in US Air Force officers’ Master’s thesis than all published academic papers before 2005). Captain NeSmith got his data from the Information Systems Designator (ISD) database maintained by the Standard Information Systems Center (SISC); the data does not include classified project and embedded systems. This database contained more data than appeared in the thesis, but I cannot find it anywhere.
Given the spiky nature of the data I’m guessing that LOC and development costs are counted in the year a project is delivered. Maintenance costs are through to financial year 1984.
The big question that jumps out of the data is “What project delivered 0.5 billion lines of Fortran in 1972?”
The LOC for Assemble suspiciously does not occur before 1965.
In the 1980s people were always talking about the billion+ lines of Cobol in use by the US Government. Over the 31 year span of this USAF data, 46 million lines of Cobol were delivered at a cost of $0.5 billion. Did another 50 arms of the government produce similar amounts of Cobol? Is the USAF under/over representative of Cobol?
The plot below shows yearly LOC against development cost, plus fitted regression lines.
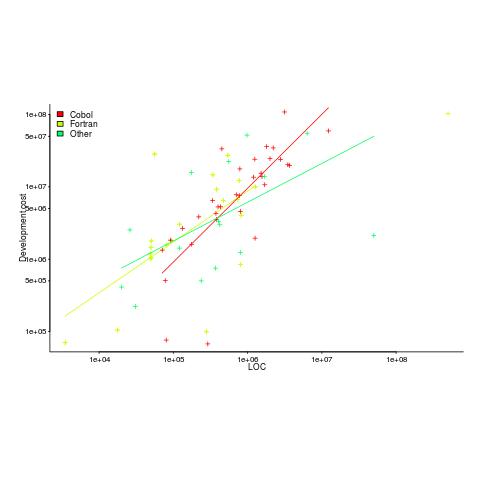
Using development cost as a proxy for effort, the coefficients of the fitted lines were close to those I fitted to Boehm’s embedded data (i.e., the exponents were lower than those listed by Boehm); Fortran 0.7, Cobol 1 and Other 0.5 (the huge Fortran outlier was excluded).
Adding Year to the regression model shows than Fortran development cost decreased by around 8% per year. Cobol may have been around 1% per year, depending on which model is chosen.
The maintenance costs can be plotted, but there is just too much uncertainty about them to say anything sensible (was inflation taken into account, how heavily used were the programs {more usage find more faults and demand for more features}, etc.).
NeSmith’s thesis contains a lot more data. The reproduction quality is not great, so the numbers have to be typed in. If you find any bugs in my data+code, please let me know and if you type in any of the other tables I would love a copy.
Is the ISO C++ standard’s committee past its sell by date?
The purpose of having a standard is economic. The classic (British) example is screw threads, having a standard set of screw threads means that products from different manufacturers are interchangeable and competition drives down prices; the US puts more emphasis on standards being an enabler of people interchangeability, i.e., train people once and they can use the acquired skills in multiple companies.
In the early days of computing we had umpteen compilers for Cobol, Fortran and then Pascal and then C and then C++. There were a lot of benefit to be had getting the vendors signed up to support a single standard for their language (of course they still added bells and whistles to ‘enhance’ their offerings). Language standard’s meeting were full of vendors, with a few end users (mostly from large corporations and government).
Fast forward to today and the ranks of compiler vendors has thinned significantly. Microfocus dominates Cobol, Fortran is dominated by a few number cruncher oriented companies, Pascal die hards cling on in surprising places, C vendors are till in double figures (down by an order of magnitude from its heyday) and C++ vendors will soon be accurately countable by Trolls (1, 2, 3, many).
What purpose does an ISO language standard serve in a world with only a few compilers? These days the standard is actually set by the huge volume of existing code that has to be handled by any vendor hoping to be adopted by developers.
The ISO C++ committee has become the playground of bored consultants looking for a creative outlet that work is not providing. Is there any red blooded developer who would not love spending a week, two or three times a year, holed up in a hotel with 100+ similarly minded people pouring over newly invented language features?
Does the world need all these new features in C++? Fortunately for the committee there are training companies who like nothing better than being able to offer ‘latest features of C++’ courses to all those developers who have been on previous ‘latest features of C++’ courses. Then there is the media, who just love writing about new stuff, there is even an ‘official’ C++ Standard news outlet.
In the good old days compiler vendors loved updates to the language standard because it gave them an opportunity to sell upgrades to customers; things are a bit different in the open source compiler market. What is the incentive of an open source compiler vendor to support features added by an ISO committee? In the past there has been a community expectation that it will happen, but is the ground swell of opinion enough to warrant spending resources on supporting new languages? Perhaps the GCC and LLVM folk will get together and mutually agree not to waste resources being the first mover.
Would developers at large notice if the C++ committee didn’t do anything for the next 10 years?
The Javascript ECMAscript standard also has a membership that includes many end users. In this case I suspect companies are sending people to make sure that new languages features don’t impact large code bases and existing investment in ways of doing things.
Update: I’m not saying that C++ language and libraries should stop evolving, but questioning the need to have an ISO Standard’s committee in a world of Open Source and a small number of compilers (that is likely to only become fewer).
AEC hackathon: what do the coloured squiggles mean?
I was at the AEC hackathon last weekend. There were a whole host of sponsors, but there was talk of project sponsorship for teams trying to solve a problem involving London’s Crossrail project. So most of those present were tightly huddled around tables, intently whispering to each other about their crossrail hack (plenty of slide-ware during the presentations).
I arrived at hacker time (a bit later than all the keen folk who had been waiting outside for the doors to open from eight’ish) and missed out on forming a team. Talking to Nik and Geoff, from the Future Cities Catapult (one of the sponsors), I learned about the 15 sensor packages that had been distributed around the building we were in (Intel Photon+Smartcitizen sensor kits, connected via the local wifi).
These sensors had been registered with the Smart Citizen platform and various environmental measurements, around each sensor, was being recorded at 1 minute resolution. The sensors had been set up a few days earlier, so only recent data was available.

The Smart Citizen dashboard provided last recorded values and a historical plot for each sensor on its own (example here). The Future Cities guys wanted something a bit more powerful, and team Coloured Squiggles set to work (one full-time member, plus anyone who dawdled within conversation range).
It did not take long, using R, to extract and plot the data from various sensors (code). The plot below shows just over a day’s worth of data from the sensor installed in the basement (where the hackathon took place). The red line is ambient light (which is all internal because we are underground), yellowish is sound level (the low level activity before the lights come on is air-conditioning switching on ready for Friday morning, there is no such activity for Saturday morning), blue is carbon monoxide (more about that later), green is nitrogen dioxide and purple is humidity. Values have been normalised.
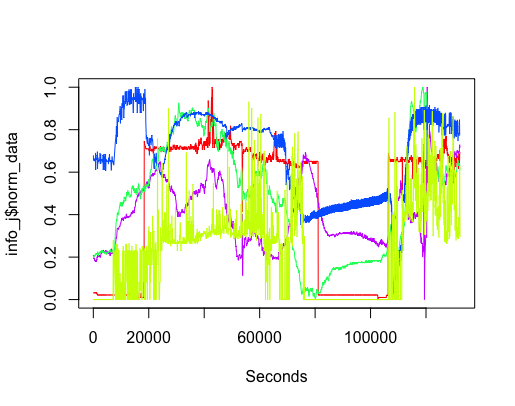
The interesting part of the project was interpreting the squiggly lines; what was making them go up and down. Nik was a great source of ideas and being involved with setting the sensors up knew about the kind of environment they were in, e.g., basement, by the window (a source of light) and on top of the coffee machine (which was on a fridge, whose cooling motor on/off cycling we eventually decided was causing the periodic nighttime spikes in the sound level seen in yellow below {ignore the x-axis values}).
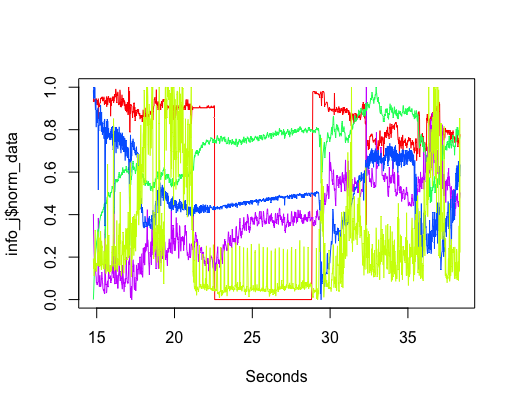
The variation in the level of Carbon-Monoxide was discussed a lot. IoT sensors are very low cost, and so it is easy to question the quality of their output. However, all sensors showed this same pattern of behavior, although some contained more noise than others (compare the thickness of the blue lines in the above plots). One idea was that CO is heavier than air and sinks to the floor at night and gets stirred up in the morning, but Wikipedia says it is not heavier than air. Another idea was that the air-conditioning allows fresh outside into the building in the morning, which gets gradually gets filtered.
The lessons learned was that a sensor’s immediate environment can cause all sorts of unexpected variation in its output. The only way to figure out what is going on is by walking around talking to the people who occupy the same space as the sensor.
The final version provided a browser based interface, allowing individual devices and multiple sensor output to be selected (everything is on github).
Recent Comments