Archive
Cost/performance analysis of 1944-1967 computers: Knight’s data
Changes In Computer Performance and Evolving Computer Performance 1963-1967, by Kenneth Knight, are the references to cite when discussing the performance of early computers. I suspect that very few people have read the two papers they are citing (citing without reading is a surprisingly common practice). Both papers were published in Datamation, a computer magazine whose technical contents could rival that of the ACM journals in the 1960s, but later becoming more of a trade magazine. Until the articles appeared on bitsavers.org they were only really available through national or major regional libraries.
Both papers contain lots of interesting performance and cost data on computers going back to the 1940s. However, I was not interested enough to type in all that data. This week I found high quality OCRed copies of the papers on the Internet Archive; my effort was reduced to fixing typos, which felt like less work.
So let’s try to reproduce Knight’s analysis of the data (code and data). Working in the mid-1960s, I imagine Knight did everything manually, with the help of mechanical calculators. I have the advantage of fancy software, a very fast computer and techniques that were invented after Knight did his analysis (e.g., generalized linear methods).
Each paper contains its own dataset: the first contains performance+cost data on 225 computers available between 1944 and 1963, while the second contains this information on 63 computers available between 1963 and 1967.
The dataset lists the computer name, the date it was introduced, number of operations per second and the number of seconds that can be rented for a dollar (most computer time used to be rented, then 25 years later personal computers came along and people got to own one, now, 25 years after that Cloud is causing a switch back to rental per second).
How are operations measured? The MIPS unit of measurement did not start to be generally used until the 1980s. Knight used 30 or so system characteristics, such as time to perform various arithmetic operations and I/O time, plus characteristics of scientific and commercial applications to calculate a value considered to be a representative scientific or commercial operation.
There is no mention of how seconds-per-dollar values were obtained. Did Knight ask customers or vendors? In a rental market, I imagine vendor pricing could be very flexible.
In the 1970s people started talking about Moore’s law, but in the 1960s there was Grosch’s law: Computer performance increases as the square of the cost, i.e., faster computers were cheaper to rent, for a given number of operations. Knight set out to empirically check Grosch’s law, i.e., he was looking for a quadratic fit.
Fitting a regression model to the 1950-1961 data, Knight obtained an exponent of 2.18, while I obtained 2.38 for commercial operations (using a slightly more sophisticated model, because I could); time on faster computers was cheaper than Grosch claimed. For scientific operations, Knight obtained 1.92, while I obtained 3.56; despite trying all sorts of jiggery-pokery I could not get a lower value. Unless Knight used very different values to the ones published in the ‘scientific’ columns, one of us has made a big mistake (please let me know if my code is wrong).
Fitting a regression model to the 1963-1967 data, I get figures (both around 2.85 and 2.94) that are roughly in agreement with Knight (2.5 and 3.1). Grosch’s law has broken down by 1963 (if it ever held for scientific operations).
The plot below shows operations per second against operationsseconds per dollar for the 1953-1961 data, with fitted lines for some specific years. It shows that while customers get fewer seconds per dollar on faster computers, the number of operations performed in those seconds is raised to the power of two+ (code and data):
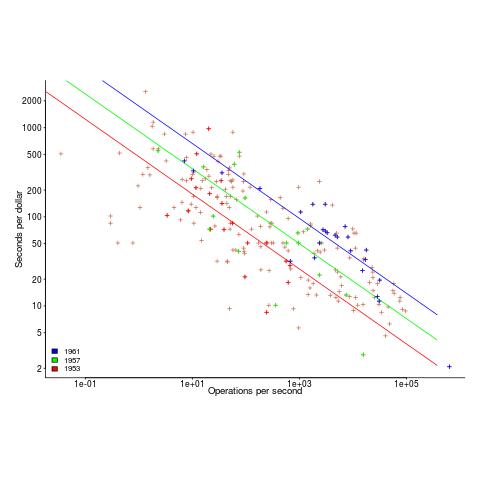
What other information can be extracted from the data? The 1953-1961 data shows seconds per dollar increased, over the whole performance range, by a factor of 1.15 per year, i.e., 15%, for both scientific and commercial; the 1963-1967 year-on-year increase jumps around a lot.
The dance of the dead cat
The flagging of unspecified behavior in C source by static analysis tools (i.e., where the standard specifies two or more possible behaviors for translators to choose from when generating code) is starting to rather get sophisticated, some tools are working out and reporting how many different program outputs are possible given the unspecified behavior in the source (traditionally tools simply point at code containing an instance of unspecified behavior).
A while ago I created a function where the number of possible different values returned, driven by one unspecified behavior in the code, was a Fibonacci number (the value of the function parameter selected the n’th Fibonacci number).
Weird ways of generating Fibonacci numbers are great for entertaining fellow developers, but developers are unlikely to be amused by a tool that flags their code as generating Fibonacci possible values (rather than the one they are expecting).
The possibility of Fibonacci different values relies on the generated code cycling through all possible behaviors, allowed by the standard, at runtime. This can only happen if program execution uses a Just-in-Time compiler; the compile once before execution implementations used by most developers get to generate far fewer possible permitted values (i.e, two for this particular example). Who would be crazy enough to write a JIT compiler for C you ask? Those crazy people who translate C to JavaScript for one.
To be useful for developers who are not using a JIT compiler to execute their C code, static analysis tools that work out the number of possible values that could be produced are going to have to support a code-compiled-before-execution option. Tools that don’t support this option will have what they report dismissed as weird possibilities that cannot happen in the developer’s world.
In the code below, does setting the code-compiled-before-execution option guarantee that the function Schrödinger always returns 1?
int x; int set_x(void) { x=1; return 1; } int two_values(void) { x=0; return x + set_x(); // different evaluation order -> different value } bool Schrödinger(void) { return two_values() == two_values(); } |
A compiler is free to generate code that returns a value that depends on whether two_values appears as the left or right operand of a binary operator. Not the kind of behavior an implementor would choose on purpose, but inlining both calls could result in different evaluation orders for the two instances of the code contained in what was the function body.
Our developer friendly sophisticated static analysis tool vendor is going to have to support a different_calls_to_same_function_have_same_behavior option.
How can a developer find out whether the compiler they were using always generated code having the same external behavior for different instances of calls, in the source, to the same function? Possibilities include reading the compiler source and asking the compiler vendor (perhaps future releases of gcc and llvm will support a different_calls_to_same_function_have_same_behavior option).
As far as I know (not having spent a lot of time looking) none of the tools doing the sophisticated unspecified behavior stuff support either of the developer friendly options I am suggesting need to be supported. Tools I know about include: c-semantics (including its go faster commercial incarnation) and ch2o (which the authors tell me executes the Fibonacci code a lot faster than c-semantics; last time I looked ch2o needed more installation time for the support tools it uses than I was willing to spend, so I have not tried it); the Cerberus project has not released the source of their system yet (I’m assuming they will).
C Standard meeting, April 2016
I was at the ISO C Standard’s meeting in London this week; it has been five years since I last attended a WG14 meeting, when it was last in London (my jet-setting standard’s meeting days are long gone). Around 20 people attended, of which slightly more than half I knew from previous meetings. Given how unchanging the membership was for so long, this is a large change and it’s great to see so many new people being interested in C (including and open source vendor, RedHat). There is also a change of convener since my last meeting; David Keaton is a long-standing member and as meeting chair he kept things motoring along.
The format of each day, after the first morning, was to spend an hour at the start of each morning and afternoon working on Defect Reports, break and then work through documents in the pre-meeting mailing.
The topic of note on Monday afternoon was a proposal to add support for the type short float in C2X. There is a lot of hardware support for 16 bit floating-point operations (e.g., SSE instructions) and C is behind the curve on this. There was consensus to move forward on this proposal.
Tuesday was taken up by discussing proposals under the general heading of clarifying the C memory object model; various papers by a formal methods group at Cambridge University that I have written about before. I had misunderstood the intent behind the papers; the Prof running the project wanted to fix the programming world by changing the C Standard (I thought he just wanted clarification of what the standard said). While fixing the programming world is a commendable goal, messy reality and very strong interests for not changing existing behavior are likely to maintain the status quo. Talking to the post grad working on the project, they seem to be doing all the right things, so we could be seeing some very interesting results (a major threat to success is the sheer volume of material that has to be covered).
Wednesday covered the charter for revising C, various proposals for new features in C2X (mostly lots of thread based stuff), conversion of the document to LaTeX (currently in nroff/groff; there was no sentiment to follow C++ and put the draft on a public GitHub repo). When C89 became an ANSI standard, before C90 became an ISO standard, Rex Jaeschke handed out a floppy of the C89 nroff sources to those attending one of the meetings (I forget which). Unless you happen to have an AT&T 3b2 and know which options to give nroff, you are very unlikely to be able to generate something that looks like C89.
Thursday covered another C2X proposal, closures using syntax and semantics supported by C on Apple (Borland got there first by supporting the __closure qualifier on pointers). In the afternoon, we had a presentation of the latest C binding to the guidance on avoiding vulnerabilities in programming languages work going on in WG23. WG23 wanted WG14 to endorse this document and take ownership of it; lots of push back on this, and all they got was a request to WG14 members to send any suggested improvements to WG23.
The next WG14 meeting is during October in Pittsburgh, and I have no idea when the next meeting will be held in the UK (unlikely to be within three years).
Tools that help handle floating-point dragons
There be dragons is a common refrain in any discussion involving code containing floating-point. The dragons are not likely to disappear anytime soon, but there has been a lot of progress since my 2011 post and practical tools for handling them are starting to become available to developers who are not numerical analysts.
All the techniques contain an element of brute force, very many possibilities are examined (cloud computing is starting to have a big impact on how problems are attacked). All the cloud computing on the planet would not make a noticeable dent in any problem unless some clever stuff was done to drastically prune the search space.
My current favorite tool is Herbie, if only because of the blog posts describing some of the techniques used (it’s currently limited to code without loops; if you need loop support check out Rosa).
It’s all very well having the performance of your floating-point code optimized, but who is to say nasty problems are not lurking in unexplored ranges of the underlying formula. Without an Oracle capable of generating the correct answer (whatever that might be; Precimonious has to be provided with training inputs), the analysis can only flag what is considered to be suspicious behavior. Craft attempts to detect cancellation errors, S3FP searches for input values that produce results containing large relative error and Rangelab simply provides bounds on the output values calculated from whatever input it is fed.
Being interested in getting very accurate results is a niche market. Surprisingly inaccurate results are good enough for many people and perhaps we should be using a language designed for this market.
Perhaps the problem of efficiently and accurately printing floating-point numbers might finally have just been solved.
Ada updated to support undefined behavior
The Ada language has now almost completely disappeared from developer consciousness and the Ada Standards’ committee has decided this desperate situation calls for desperate actions.
Undefined behavior in programming languages has been getting a lot of publicity over the last few years. It might not be good publicity, but the Ada committee has taken to heart the old adage ‘The only thing worse than being talked about is not being talked about.’
While the Ada standard does not use the phrase undefined behavior, it does contain a very close equivalent. The Ada community has bitten the bullet and decreed that constructs previously denoted by the term bounded error shall henceforth be referred to as undefined behavior. Technically, constructs generating a bounded error have effectively always been undefined behavior, but the original positioning of Ada as a sophisticated language suitable for critical applications required something less in-your-face unsafe sounding.
Will this minor change of wording (ISO rules are very strict on what changes can be made to published standards without going through long winded voting procedures) make any difference? I guess it will enable Ada users to jump on the ‘undefined behavior’ bandwagon (their claims that Ada was better because it did not contain undefined behavior always has the effect of annoying people, rather than generating any interest in changing languages).
I think there is a bigger public perception problem than the terminology used to denote undefined behavior. Ada Lovelace was born 200 years ago and gets lots of publicity as the first programmer; somehow this association with Lovelace has transferred to the language named after her, generating a perception of an old, fuddy-duddy language (being strongly typed has not helped, but this feature does appear to be coming back into fashion).
The following are some numbers from a while ago (both standards have been revised since these measurements were made).
In the Ada 2005 Standard there are:
36 occurrences of bounded error. 53 occurrences of the subsection header Erroneous execution and 116 occurrences of erroneous. 343 occurrences of implementation-defined. 373 occurrences of may, some of which describe optional behavior. 22 occurrences of must some of which that read as-if shall was intended. 38 occurrences of optional. zero occurrences of processor dependent and processor-dependent. 1,018 occurrences of shall of which 131 have the form shall not. 452 occurrences of should. 8 occurrences of undefined, one referencing to an undefined range, three having the form undefined range and the rest occurring in annexes (also see bounded error). • 89 occurrences of unspecified.
In the C99 Standard there are:
zero occurrences of bounded error. 3 occurrences of erroneous. 163 occurrences of implementation-defined. 862 occurrences of may. 1 occurrence of must. 34 occurrences of optional. zero occurrences of processor dependent and processor-dependent. 596 occurrences of shall of which 71 have the form shall not. 63 occurrences of should. 183 occurrences of undefined. 98 occurrences of unspecified.
In the C++ 2003 Standard (which now contains many more pages) there are:
zero occurrences of bounded error. 5 occurrences of erroneous. 236 occurrences of implementation-defined. 371 occurrences of may. 111 occurrences of must. 30 occurrences of optional. zero occurrences of processor dependent and processor-dependent. 779 occurrences of shall of which 211 have the form shall not. 38 occurrences of should. 195 occurrences of undefined. 113 occurrences of unspecified.
Explaining the decline of German comments in LibreOffice
The LibreOffice suite of office programs traces it origins back to StarWriter, first launched in 1985 by a German company. Given its German parentage it’s no surprise that the source code contains comments written in German.
There has been a push by the LibreOffice folks to convert the German comments to English comments. The plot below shows the number of German comments in the source of LibreOffice over time (release version numbers at the top and red line is the least squares fit of an exponential; code and data).
I am not only surprised to see such a regular decline in the number of German comments, but also that the decline is exponential.
The pattern of behavior may be driven by those doing the work:
Perhaps the issue is the skill required to convert the comments:
I find it hard to believe any of these mechanisms. Suggestions for easier to believe mechanisms welcome.