Archive
Operator assignment may be in the next Ada standard
WG9, the Ada Standard committee, are looking into adding support for operator assignment in the next revision of the language standard. Ada was designed back in the day when C’s operator assignments, such as +=, were a novelty (all the languages we know today that follow C’s lead, including choice of operator precedence, did not yet exist); developers using serious languages knew that typing everything out in full was good for you.
It’s amazing to read about “… those who have been damaged by terser languages…”, in the proposal comments. Do I only think that My_Package.My_Array(I).Field +:= 1; is so much easier to read than My_Package.My_Array(I).Field := My_Package.My_Array(I).Field + 1; because my brain has been damaged? In the second statement I have to parse two subexpressions and notice that they refer to the same object, while the first statement only requires me to parse one subexpression and the +:= operator tell me that something is being added to its value. The first statement requires a lot less effort and is likely to be less error prone (I bet Ada programs make cut and paste error just like the rest of us).
Did you notice the use of round brackets to specify an array index? Yes, the eighties were the decade when the programming language world was badgered into being politically correct and only require the use of characters that appeared on every European country’s keyboard.
The Ada proposal started out following the C convention, e.g., +=, *=, etc, then switched to :+, :*, etc. The assignment token in Ada is := and there is a logic to switching out the = for another operator. However, I would argue that +:, *:, etc would be a less error prone ordering or characters. People pay more attention to the first character in a sequence and somebody in a hurry may not notice that the colon is not followed by a =; putting the ‘unexpected’ character first is more likely to catch reader attention.
Another proposal is for the @ token to act as a placeholder. The only place I can see this being useful on any regular basis is in bitwise manipulation: My_Package.My_Array(I).Field := (@ << 16) or @ ; (Ada does not support << as an operator, so reality is a bit more complicated than this). I don't think there are enough situations where placeholders would be useful to warrant using a solution that is more complicated than operator assignment.
One proposed advantage of the new fangled operators is making life easier for non-Ada users (see the discussion in the proposal comments). The I have put lots of efforts into Ada, why should others have it easy die-hards are fighting a rear guard action to make sure life is not too easy for newcomers.
Researching just to create software patents
I was recently reading the paper “ARC++: Effective Typestate and Lifetime Dependency Analysis” (cannot find a public pdf now). What caught my attention was the fact it involved static analysis of C++ source, something that few researchers get involved in because of the technical complexity of parsing C++. I wanted to know more and guess what popped up near the top of a Google search, a patent with almost the same title as the paper and with many of the paper’s authors listed as the inventors!
As far as I can tell the Claims section of the patent does not list anything new or novel (in fact the only prior art listed was added by the patent examiner). It is not hard to understand why this patent exists; the main paper author works in an NEC research laboratory and commercial research labs have to ‘pay’ their way by producing patents that the parent company can brandish at competitors.
At least it looks like the patent was applied for before the paper was published. The most extreme case of paper published followed by patent application, sometime later, I have encountered was during my spell as an adviser to the Monitoring Trustee appointed by the European Commission in the EU/Microsoft competition court case. One of the non-patented innovations being claimed by Microsoft (or perhaps the patent had been granted, my memory is fuzzy) was for something described in a PhD thesis whose author went to work for Microsoft, after completing his PhD; this was back in the day when typing a couple of technical terms and the name listed as the patent inventor into a search engine was still something new for bean counters.
Lisp and functional languages discourage free riders
While many developers have a favorite programming language, there are a few who believe they have found the One True Language and refuse to even consider coding in another language.
Why is the One True Language invariably a dialect of Lisp or a functional language?
I think the reason is the same as why strict churches are strong, both these language families make life difficult for free riders, i.e., the casual programmer.
Superficially Lisp-like languages look unwelcoming because of all those brackets and the tiresome reverse polish notation, but once past these surface speed bumps life is not a bed of roses, there are mind bending language challenges to master at every abstraction level; developers get sucked into the community working on mastering each level (this suggests an alternative explanation that coding in Lisp is a way of continuing to play Dungeons & Dragons while appearing to work).
True functional languages don’t have global variables and certainly don’t let you create stateful information. The self-flagulation no global variable languages have a limited clientèle; its the writing of programs that don’t make use of side-effects (e.g., iteration via recursion, not explicit loops) that marks out the true community members; a short conversation with a developer is enough to tell whether they are one-of-us who joyfully tells the world of their latest assignment-free solution to an apparently intractable problem (intractable in the sense of appearing to require the use of assignment statements). There are always umpteen different ways of writing something in functional languages, providing plenty of scope for sects to splinter off by requiring disciples to follow a particular approved style.
Why have Lisp and functional programming continued to survive for so long? Some interesting research on communal societies has found a correlation between the number of costly requirements entailed by community membership and community longevity, the greater the number of costly requirements the longer a community survives. Having sunk so much time and effort into the costly signaling required for community membership, people are loath to leave it all behind.
Citation patterns in my two books
When writing my C book, I cited any paper or book whose material I made use of and/or that I thought would be useful to the reader. One of the rules for academic papers is to cite the paper that ‘invented’ the idea; this is intended to incentivize researchers to work hard to discover new things that will be cited many times (citation count is a measure of the importance of the work and these days a metric used when deciding promotions and awarding grants).
When I started writing the C book the premier search engine was AltaVista, with Google becoming number one a few years before the book was completed. Finding papers online was still a wondrous experience and Citeseer was a godsend.
The plot below shows the numbers of works cited by year of publication, for the C book.
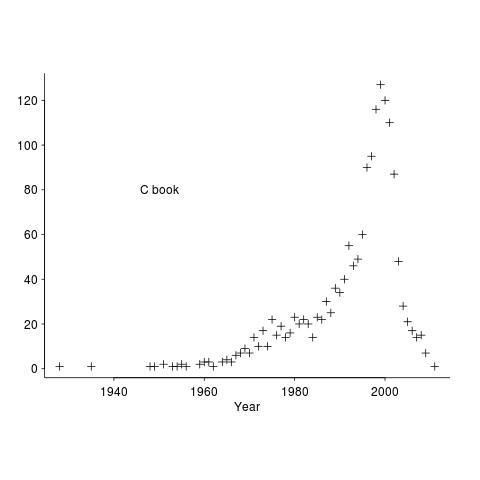
These days all the information we could possible need is said to be online. I don’t think this is true, but it might be a good enough approximation. But being online does not mean being available for free, a lot of academic papers remain behind paywalls.
It used to be possible to visit a good University library and copy papers of interest (I have a filing cabinet full of paper from the C book). Those days are gone, with libraries moving their reference stock off-site (the better ones offer on-premise online access).
My book on empirical software engineering is driven by what data is available, which means most cited work is going to be relatively new. There is another big factor driving the work I cite this time around; I am fed up with tax payer funded research ending up behind paywalls, so I am only citing papers that can be downloaded for free (in practice they also have to be found by a search engine or linked to from somewhere or other) and when the ‘discovery’ paper is not available for download I cite a later work that is.
The plot below shows the numbers of works cited by year of publication, for the empirical software engineering draft book.
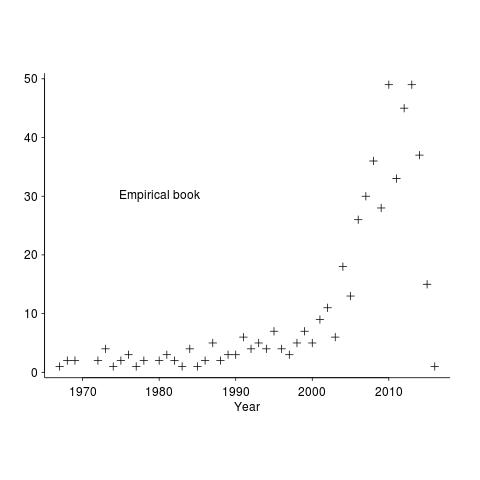
The rising slope is much sharper for the latest book. I think most of the difference is driven by the newness of the subject, software researchers tend to be very good (at least the non-business department ones) at making pdfs available for download.
Another factor might be how Citeseer and Google Scholar cross reference papers; Citeseer links to works cited by a paper (i.e., link back in time), while Google Scholar links to works that cite the paper (i.e., link forward in time).
Recent Comments