Archive
Joke: Student subjects in software engineering experiments
Most academic experiments in software engineering use the students available to the researcher as subjects, often classifying first year as novices and final year or postgrads as experts. If professional developers (i.e., non-student) subjects are used the paper will trumpet this fact; talk of comparing novices and experts is the give-away for an all undergraduate subject line-up. Most computing academics don’t write much software, so they are blissfully ignorant that they and their students are novices compared to a professional developer with a couple of years experience.
Results from well designed and executed experiments can reasonably be extended to cover people who share the skills used by subjects in the experiment. Becoming an expert programmer takes several years of continuous (i.e., several hours a day) practice. Using real experts in a programming experiment means that no measurable change in programming skill will occur during the experiment, while novices are likely to noticeably learn during the experiment and thus introduce unwanted sources of variation into the results. Of course novices will also take longer and are likely to have patterns of behavior that are not yet been selectively tuned to something that works in practice.
There is also an elephant in the room of student subjects in software engineering; some of the students are never going to get jobs in software engineering because they are completely useless at it. How does a student manage to get a degree in a software related subject and be unemployable as a software engineer? Money. Students are attracted by the money and lifestyle they hear a job in software engineering will offer and many Universities are happy to treat the computing department as a cash cow by offering courses that allow students to concentrate on “strategic” subjects and avoid having to get involved in nitty gritty details like programming. The University is probably defrauding some students by accepting them for a software related degree course.
My experience is that professional developers are happy to donate some time to taking part in a software engineering experiment. They just have to be asked, of course I do have the advantage of actually knowing some professional software developers.
Finding team members and an idea at a hackathon
You have chosen a hackathon (discussed in a previous post), your application to attend was accepted (usually only turned down because the venue is full), now what do you do? If they are organized (some are not) the people running the event will have a web page containing a list of possible problems/challenges, possible sources of data, judging criteria and other information; read this several times. It is helpful to turn up on the days with several possible project ideas, so keep you mind open in the weeks/days before the event to workable ideas. Depending how keen you are you might also search the Internet for information that could help.
Most events have a rule that all coding must be done on the day, i.e., no turning up on the day with a half finished App.
So you arrive at the venue and sign in, what next? You need team members (assuming you have not formed team beforehand). Yes, you are usually allowed to work on your own but why bother attending if you plan to do this, you might just as well work from home and just turn up to present at the end.
My choice of possible team members is driven by my reason for attending hackathons, I enjoy building software systems. So I look for other developers and perhaps a subject domain expert for advice. My social mingling gets straight to the point, after saying hello I ask the person in front of me what language they like to code in, maybe 20% give a reply that shows they are a developer.
If you reason for attending is to teach then there will be people who are “there to learn”, if you like listening to other people rabbit on about their ideas then there will be “ideas people” and if you don’t get enough of non-technical managers during the week you will probably have first pick of those present. In theory everybody should want a “designer” on their team, in practice people who cannot code but think they can do “something” say they are “designers”.
If you are looking to build something I recommend avoiding anybody who cannot code (or build hardware if at a hardware hack) like the plague. These people soak up a huge amount of discussion time and when it comes down to it do not contribute much towards what is being built (I have seen non-developers make a crucial contribution to a team, but then monkeys will eventually type Shakespeare). Of course, outside of a hackathon context non-developers are needed.
I recommend keeping your team small, no more than four people. Depending on what you are building it may not be possible to split the work between more than two people (I have won several times in a team of two), or perhaps three. If you find yourself in a group of more than four I suggest that you agree to kick around ideas together and then split into smaller teams, it is unlikely that everybody will be interested in working on the same idea.
You will need an idea for what to build. Don’t be shy about sharing your ideas and asking other people what their ideas are. This is where letting things tick over in your mind before the event helps; you will probably have a couple of ideas to start things off.
Everybody thinks their own ideas are great and that other people at the hackathon will steal them if they can. In practice convincing other people that your idea is worth their time is hard work; be prepared to sell your idea to a group of people who are as skeptical, but willing to go for it, as you are.
I have never seen it written down, but there is a view that what you build has to have something unique about it, at least if you want to be win in some category. Be prepared to feel very deflated when somebody points you at a site implementing exactly what you are proposing, only much better; this happens to me on a regular basis.
So you are part of a team, have some ideas and are all sitting around a table plugging in your laptops. You will probably spend several more hours talking things through and maybe searching the internet. You might still be talking 10 hours later (only happened to me once before).
At a hackathon you are always free to get up and leave your team. Of course as time goes by other teams are more likely to have jelled and be less inclined to accept a new member. If things are really going nowhere, you can always go home.
To be continued…
Finding and choosing a hackathon to attend
Lots of developers seem to be interested in Hackathons but are not sure where to find out about them or what’s involved. This is part one of a summary of what I know about hackathons, based on a couple of years of going to them (mostly in and around London, my participation was sporadic until last year); the next article will offer some suggestions for what to do at a hackathon.
Hackathons-and-Jams UK is a great source of information about London based events; its a group on meetup.com which is the site to find out about out-of-work computer related get togethers; some of the other meetup groups that host events include: Data Science London, DataKind UK and Microservices Hackathon.
Eventbrite is often used by event organizers for attendee sign-up and searching this site using the obvious keywords is worthwhile.
The UK Hackspace Foundation lists more local groups meeting on a regular basis, an some hold hackathons.
Now you have a list of forthcoming events, which ones are worth attending (assuming a place is free; this year’s Battlehack ‘sold-out’ in six seconds)? I choose events based on how interesting they look and given a choice prefer those where I will be more relaxed (e.g., likely to have a comfortable place to sit, reasonable food and no noise) and much prefer 24 hr hacks (which usually start Saturday and finish Sunday); evening events are over almost before they have started. Events can be roughly classified as follows:
- Data driven: sponsors provide lots of data relating to a topic, or access to an API, and people have to use this to create something,
- Create anything: completely open-ended, as long as you make use of one of the sponsor’s API in some form,
- Create anything in hardware: a hardware hack essentially boils down to hanging peripherals off a single board computer and making something happen.
I cannot give you any useful advice about what interests you (apart from suggesting that you ignore details of what the actual prizes are, just have fun and aim to produce something that wows the crowd), but I can provide a few tips on evaluating venues.
My top two venues are The Hub Westminster (very comfy seats, a great atmosphere, plenty of local shops and food often good {but Pret does get tedious}) and Level 39 at Canary Wharf (fantastic food and great views).
The venue I try to avoid is the Google Campus, a 1960s bunker packed with solid wooden furniture to deform your body and numb your behind; a very low cost venue that Google are happy to let startups to use for almost nothing in some cases.
In general events held in company/university canteens will be uncomfortable places to hack (these places are designed to get people to leave after they have eaten) and often have WiFi that cannot support too many users at the same time.
Hackathons are generally free; non-free ones are treated with suspicion (but some will return your registration fee when you turn up, a way of ensuring people will only book if they really plan to attend; it not unusual for 50% of those registered not to show up on the day). The deal is that you use the sponsors’ API (and so become familiar with their product) and they feed and water you.
Generally you get to keep copyright and any IP, although posting the code to sites such as Github is encouraged. Some financial services hacks have terms & conditions that require you to sign over your soul. Its your soul, your call.
Debian has cast iron rules for package growth & death
A plot in a paper on the growth of packages in Debian over the last 15 years caught my eye. The number of packages in growing approximately linear in time (fitted red line) while the total lines of code is each release (green line, axis on right in GigaSLOC) is growing non-linearly (I suspect exponential). The obvious conclusion is that the size of each package is also growing over time; rummaging through the data provided with the paper uncovered an increase in average package size from 25.6 to 39.4 KSLOC (the full dataset is being made available on the 15th of this month).
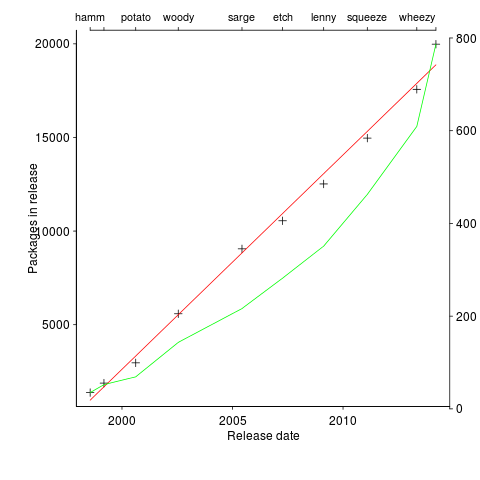
The straight line fit is excellent, explaining over 99.5% of the variance (code and data). Packages have been constantly added at the rate of 3.3 per day for over 15 years. Is there some rule that says Debian has to grow at 1,000 packages per year?
The numbers in one table showed that packages were being removed in non-trivial quantities. I wondered what the half-life of a package might be and in amongst the data provided by the paper’s authors was a list of packages shipped in each Debian release, just what was needed to create a survival curve. The answer to my package half-life question is around 11 years, as can be seen below (dashed lines are the 95% confidence interval).
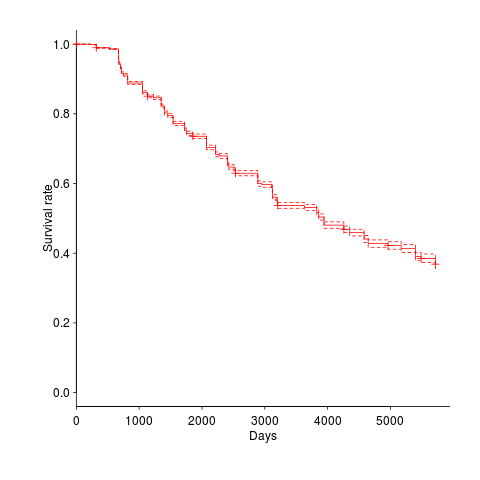
Most packages survive for two Debian releases, followed by a 10% cull and then steady decline; the survival curve is slightly concave, meaning younger packages are more likely to be removed (rather than removal being age independent). An 11 year half-life corresponds to an annual removal rate of around 9%. Is this another Debian release rule, around 10% of current packages must be removed for the next release (which means they have to be replaced by an equal number of new packages to keep that steady 3.3 per day overall increase)?
Where is all the code needed to increase the size of existing packages, and create all these new packages, coming from?
Perhaps packages are being replaced by a variant of themselves, created by somebody who has jumped in with lots of ideas (and free time) about where they want to take the application.
If there are 1,000 different kinds of application, then Debian now have 20 implementations of each of them and the next release will have one new implementation for each of them and almost two of each existing implementations will be replaced.
I wonder how much of this code is copy-and-paste, we will have to wait for the release of the full dataset (and some spare time on somebodies part).
Computing academics destined to remain software engineering virgins
If you want to have a sensible conversation about software engineering with an academic, the best departments to search are Engineering and Physics (these days perhaps also Biology). Here you are much more likely to find people who have had to write large’ish programs to solve some research problem, than in the Computing department; they will understand what you are talking about because they have been there.
A lot of academics in Computing departments hold some seriously strange views about how non-trivial software engineering is done (but not the few who have actually written large programs). I recently had a moment of insight, these academics are treating the task of creating a large program as if it were just like coding up an algorithm, but bigger. I don’t know why I did not think of this before.
Does this insight have any practical use? Should I stop telling academics that algorithms are often not that important in solving a problem (I now understand why this comment baffles so many of them)?
Why don’t many computer science academics get involved in writing large programs? Its not an efficient use of their time (as more than one has explained to me); academics are rated by the number of papers they publish (plus the quality of the publishing journals and citations, etc) and the publishable paper/time ratio for large software development projects is not attractive for risk averse academics (which most of them are; any intrepid seekers of knowledge are soon hammered down by the bureaucracy, or leave for industry).
Recent Comments