Archive
Coq used to prove that false is true
Coq, a proof system much beloved by formal methods researchers, has been used to prove that false is true. The ‘proof’ makes use of a bug in Coq, which I’m sure is being hurriedly fixed as I type.
This bug stands out from the other 4,000+ on Coq’s bug list because of what it has been used to prove; this will be a standing joke that the Coq community will have to endure for years to come. I have some sympathy for their plight, but if it results in formal methods researchers taking themselves a little less seriously and being a little more intellectually honest, then some good has come out of it.
I have had some surprising feedback about posts pointing out serious faults in claims made in papers by formal methods researchers. The feedback could be paraphrased as “They are doing important work and so these problems do not matter”. Do medical researchers get to claim whatever they like, it seems like some do like to try.
It is always worth remembering that all computer aided mathematics programs contain bugs.
C code is 90% unspecified behavior: more uninformed scare mongering
Another C coding guidelines document, another clueless blanket ban on use of code containing unspecified behavior (no link so its visibility is not increased; the 90% is a back of the envelope calculation, knock yourself out here).
The C Standard defines unspecified behavior as “… provides two or more possibilities and imposes no further requirements on which is chosen in any instance.” Given this one item of information a ban on using constructs that contain unspecified behavior appears to be a good idea (writing code where the compiler gets to choose among several possible choices of behavior does not sound like recipe for consistent program behavior).
What most people lack when thinking about unspecified behavior is an understanding of the design aims for the production of the C Standard; the aim was to be concise. An example of this conciseness is the wording for the order of evaluation of subexpressions “… the order in which side effects take place are both unspecified.”
Consider the subexpression x+y; should the compiler evaluate x first (putting its value in a register) and then y (putting its value in another register), or should it evaluate y followed by x? It most situations the final result does not depend on the choice of evaluation order and the Standard gives the compiler the freedom to choose the order that produces the best quality code.
A coding guideline that bans the use of code containing unspecified behavior bans the use of any binary operator (assignment is a binary operator in C, ruling out use of the statement z=0;). The only executable statements that could be written, following this guideline, would be calls of functions containing zero or one argument (order of evaluation is unspecified, which rules out calls containing two arguments) or global variables appearing on their own in an expression statement.
One case where operand evaluation order matters is printf("Hello")+printf("World"), which can result in either HelloWorld or WorldHello being printed (printf returns the number of characters written). This is an example of the kind of usage that the authors of coding guideline want to ban.
Coming up with guideline wording that delineates the undesirable unspecified behaviors from the harmless ones is hard. Requiring that the external behavior of code does not depend on the compiler’s choice of unspecified behavior is one possibility (now that power consumption can be an external behavior of note, this framing could be too narrow). The wording used by MISRA C is “No reliance shall be placed on … unspecified behavior”; this raises the flag that it is possible to rely on unspecified behavior and leaves it up to others to fill in the details.
Ethereum: Is it cost effective to create reliable contracts?
The idea of embedding of a virtual machine supporting user executable code inside a cryptocurrency continues to fascinate me. I attended the Ethereum workshop on using Solidity to develop dapps (distributed apps) yesterday.
Solidity seems to have been settled on as the high-level language in which programs for the EVM (Ethereum Virtual Machine) will be written, at least at launch. While Ethereum appear to know what they are doing in the design of the cryptocurrency (at least to my non-expert eyes), they are rank amateurs at language design. A good place to start learning is the rationales for Ada, Eiffel and Frink for starters.
Ethereum uses the term Contracts to describe programs executed by the EVM.
Anybody publishing a Contract that involves transferring something that has a real-world impact on their financial state (e.g., funds in cryptocurrency that are exchangeable for government backed currency) will want a high degree of confidence in the reliability of the code.
It is easy to imagine that people will be actively reverse engineering all published Contracts looking for flaws that can be exploited to siphon off funds into their personal accounts.
Writing high reliability code is time consuming and expensive. One way of reducing time/cost is to use a language that implicitly performs lots of checking, rather than requiring the developer to insert lots of explicit checks.
The following is an example of a variable definition providing information to the compiler that can be used to insert checks in the generated code (e.g., that no value outside the range 1 to 1000 is assigned to amount_to_pay); the developer does to not need to worry about explicitly adding checks in all the necessary places. This language functionality was invented in 1970 (in Pascal) but went out of fashion, for new languages, in the 1990s.
var amount_to_pay : 1..1000;
Languages such as Ada and Frink improve program reliability by providing functionality that reduces the effort developers need to invest in checking for unintended behavior.
Whatever language the code is written in, what happens if an attempt is made to assign 1001 to amount_to_pay? It does not matter whether the check is implicit or explicit, an error has occurred and has to be handled. As a developer of this code I want to know about the error (so I can fix it) and as a user of the code I do not want to lose money for executing a failed transaction.
At the moment the only Ethereum error handling solution I can think of is writing error information to the blockchain (in place of the information that would have been written on successful program execution); the user will still get charged for executing the program but at least will now have the evidence needed to obtain a refund (the user has to be charged to prevent denial of service attacks using Contracts containing a known fault).
I wonder who will find it worthwhile investing in creating the high reliability code needed for Contracts to be a viable solution to a problem?
Been invaded by mysterious sounds? You need SoundHound
Team SoundHound (Gary, Pavel and yours truly) were at the Intel Hardware Hackathon last weekend. Hardware hacks are about the peripherals that are available on the day; I grabbed one of everything and we all sat down to play with them and come up with a great gadget to build. At an Intel sponsored event the computers are obviously Galileo and Edison (which is what we ended up using).
The Intel guys had a very fixed idea about how the hackathon was to run and specified that eight projects had to be proposed and selected (by everybody present) on the Friday night and that these would be worked on over the weekend (but we were allowed to change the idea; the logic escaped me). I proposed a vibration detection project to measure the impact of passing vehicles on houses next to busy roads. Nobody on what was to become SoundHound thought this was a great idea, but it was the only idea we had and there was nothing stopping us radically changing our mind over the weekend.
Vehicles generate sound which we can hear, but buildings are damaged by the lower frequency vibrations that we sometimes feel but don’t usually hear. A microphone would be useless, what was needed was a vibration sensor and a packet of piezo vibration sensors, the SEN-09198, was provided. We did not have any amplifiers to boost the signal, so the sensors were wired directly onto the signal pins; this meant that the dynamic range of the signal was about 50 times smaller than the input could handle and our test vibrations were created by banging on the table on which the sensor sat (power spectrum of me doing just that below).
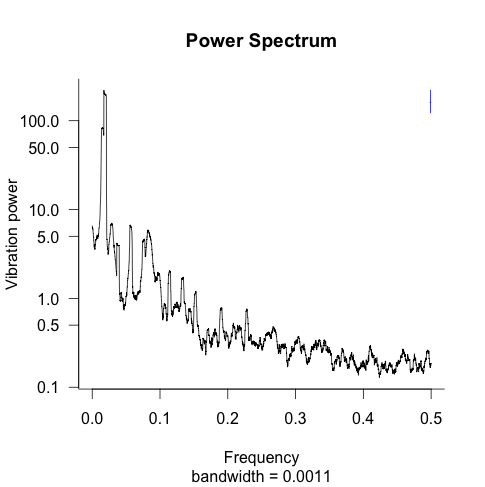
We worked away on the vehicle vibration idea waiting for something better to come along. Some household appliances contain motors that cause them to vibrate, perhaps we could detect these vibrations. The use case here was a fridge next to a wall transmitting vibration into another room which then generated a hard to pin-down noise in that room. Around this time it occurred to us that a ghost detector (everybody knows that walls vibrate when ghosts travel through them) might be a bigger market, after all occult books sell well.
IBM were an event sponsor and had people on-hand to help us set up and use Bluemix, their cloud offering. The Edison board was communicating with our laptops via wifi and this got rerouted so the data was sent to IBM’s cloud storage. Collecting everybodies vibration data meant we could do pattern matching on the power spectrum of the vibration to identify candidates for the device most likely to be generating it (whether the vibration characteristics of different devices is sufficiently different for the pattern matching to be able to distinguish them at some useful level is another matter; I imagine that the shape of a fridge causes its vibration to modulate slightly from the frequency of the local electricity supply).
One of the problems of producing a working demo at a hackathon is being held to a much higher standard of reality. Teams whose output is slideware illustrating the tenuous connection its members have to reality don’t seem to have any trouble getting unquestioning agreement that anything they propose will just work. We were asked how we would obtain the vibration data for different household devices, against which the customer data could be compared; a marketing type capable of convincingly talking about our crowd source solution would have been useful.
Late Saturday afternoon saw team SoundHound out on the streets measuring vehicle vibration. Unfortunately large lorries traveling at speed are thin on the ground in central London, also guys standing next to a laptop with wires attached to something on the ground filming everything that went past had the effect of causing drivers to slow down to low vibration speeds (rather than speeding up to get away from us).
Perhaps we should have gone with the ghost detector sale pitch. The cloud data storage could have been rebranded as The Ethereum data matrix and flashing leds added to the hand-held sensor (the penguins below send the wrong message).
If it is possible to distinguish home appliances based on their vibration characteristics, and a database is created, there is an opportunity for salesmen to systematically check each house/flat ‘listening’ for appliances that are close to failing (motors vibrate more as they wear out): “Hello Sir, your fridge/boiler/air-conditioning is getting old and this week we have a special offer on replacements…”.
The picture below shows our 3-axis vibration sensor (plastic mounting/vibration interface laser cut by Elen from the FabLab, who do brown bag lunch and learn sessions if you are ever in central London). Two axis would probably been enough, and maybe even one, but we had the sensors and wanted to impress.

Extracting the original data from a heatmap image
The paper Analysis of the Linux Kernel Evolution Using Code Clone Coverage analysed 136 versions of Linux (from 1.0 to 2.6.18.3) and calculated the amount of source code that was shared, going forward, between each pair of these versions. When I saw the heatmap at the end of the paper (see below) I knew it had to appear in my book. The paper was published in 2007 and I knew from experience that the probability of seven year old data still being available was small, but looked so interesting I had to try. I emailed the authors (Simone Livieri, Yoshiki Higo, Makoto Matsushita and Katsuro Inoue) and received a reply from Makoto Matsushita saying that he had searched for the data and had been able to find the original images created for the paper, which he kindly sent me.
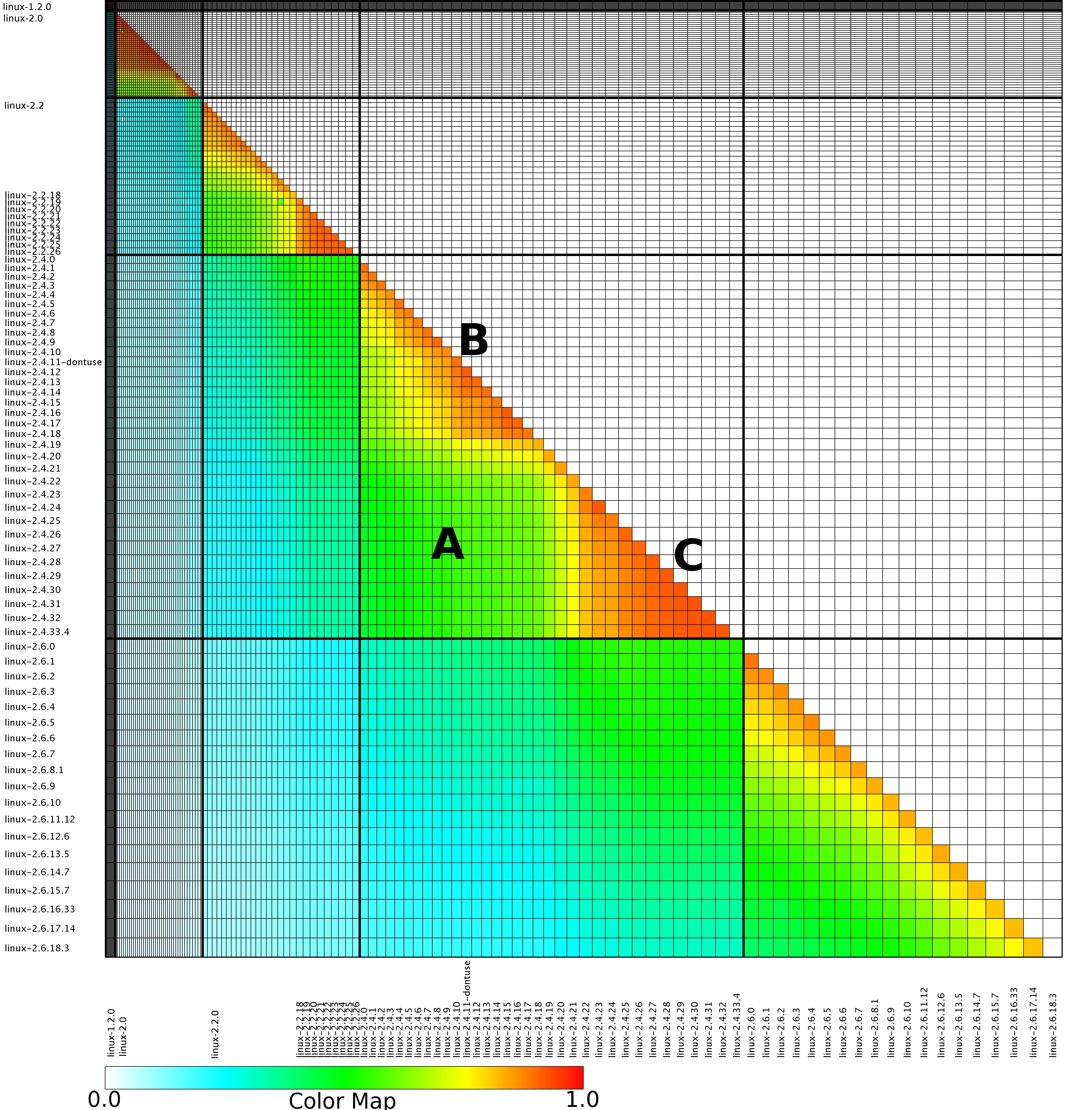
I was confident that I could reverse engineer the original values from the png image and that is what I have just done (I have previously reverse engineered the points in a pdf plot by interpreting the pdf commands to figure out relative page locations).
The idea I had was to find the x/y coordinates of the edge of the staircase running from top left to bottom right. Those black lines appear to complicate things, but the RGB representation of black follows the same pattern as white, i.e., all three components are equal (0 for black and 1 for white). All I had to do was locate the first pixel containing an RGB value whose three components had at least one different value, which proved to be remarkably easy to do using R’s vector operations.
After reducing duplicate sequences to a single item I now had the x/y coordinates of the colored rectangle for each version pair; extracting an RGB value for each pair of Linux releases was one R statement. Now I needed to map RGB values to the zero to one scale denoting the amount of shared Linux source. The color scale under the heatmap contains the information needed and with some trial and error I isolated a vector of RGB pixels from this scale. Passing the offset of each RGB value on this scale to mapvalues (in the plyr package) converted the extracted RGB values.
The extracted array has 130 rows/columns, which means information on 5 versions has been lost (no history is given for the last version). At the moment I am not too bothered, most of the data has been extracted.
Here is the result of calling the R function readPNG (from the png package) to read the original file, mapping the created array of RGB values to amount of Linux source in each version pair and calling the function image to display this array (I have gone for maximum color impact; the code has no for loops):
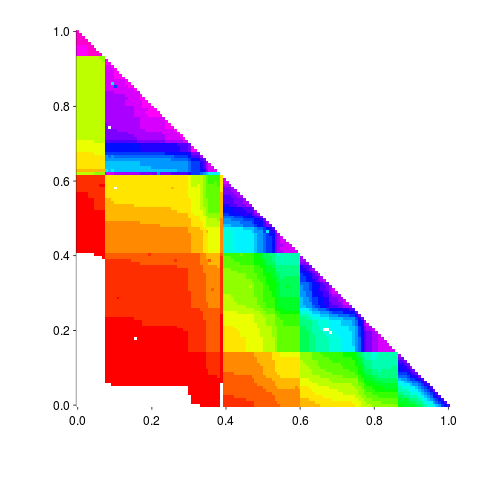
The original varied the width of the staircase, perhaps by some measure of the amount of source code. I have not done that.
Its suspicious that the letter A is not visible in some form. Its embedded in the original data and I would have expected a couple of hits on that black outline.
The above overview has not bored the reader with my stupidities that occurred along the way.
If you improve the code to handle other heatmap data extraction problems, please share the code.
Recent Comments