Archive
Hardware variability may be greater than algorithmic improvement
I’m giving a talk at COW 39 this week and it is more user friendly to include links in this summary than link to a pdf of the slides (which actually looks horrible).
Microelectronic fabrication has now reached the point where it etches and deposits handfuls of atoms (around 20 or so). One consequence of working with such a small number of atoms is that variations in the fabrication process (e.g., plus or minus a few atoms here and there) can have a significant impact on component characteristics, e.g., a transistor consumes more/less power or can be switched faster/slower. It might be argued that things will average out over the few hundred+ million components inside a device and that all devices will be essentially the same; measurements show that in practice there is a lot of variation across the devices.
Short version: Some properties of supposedly identical microelectronic devices now vary by around 10% and this variability is likely to get larger in the future.
Nearly all published papers involving computer system power measurement are based on measuring a single system. Many of the claimed algorithmic improvements are less than 10%, i.e., less than the expected variation in power consumption across supposedly identical devices/systems. These days any empirical paper involving power consumption has to include measurements from many devices/systems if any credibility is to be given to the findings.
The following measurement data has been found while researching for a book (code and data used for talk); a beta version of the pdf will be available for download real soon now.
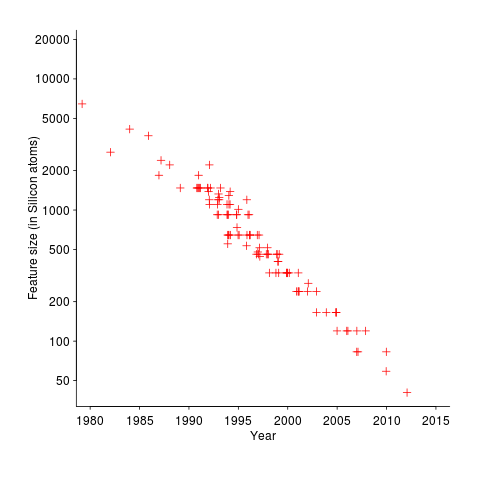
The following plot shows feature size, in Silicon atoms, of released microprocessors. Data from Danowitz et al.
A study by Wanner, Apte, Balani, Gupta and Srivastava measured the power consumed by 10 separate Amtel SAM3U microcontrollers at various temperatures (embedded processors get used in a wide range of environments). The following plot shows how power consumption varied between processors at different temperatures when idling and executing. The relationship between the power characteristics of different processors changes with temperature; a large amount when idling and a little bit when executing.
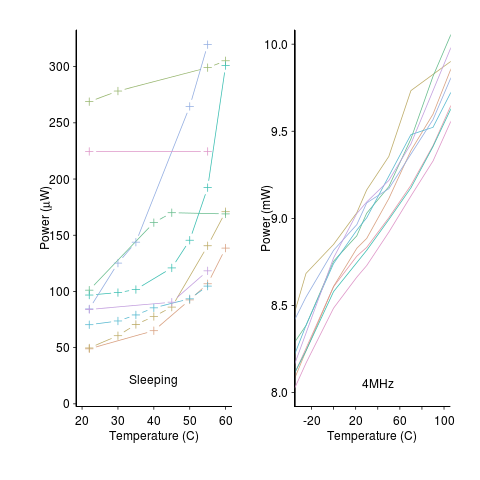
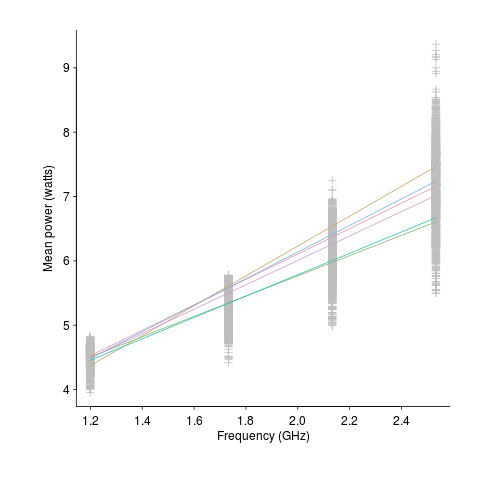
A study by Balaji, McCullough, Gupta and Agarwal measured the power consumption of six different Intel Core i5-540M processors, running at various frequencies, executing the SPEC2000 benchmark. The lines in the following plot were fitted to the data (grey crosses) using linear regression. The relationship between the power characteristics of different processors changes with clock frequency.
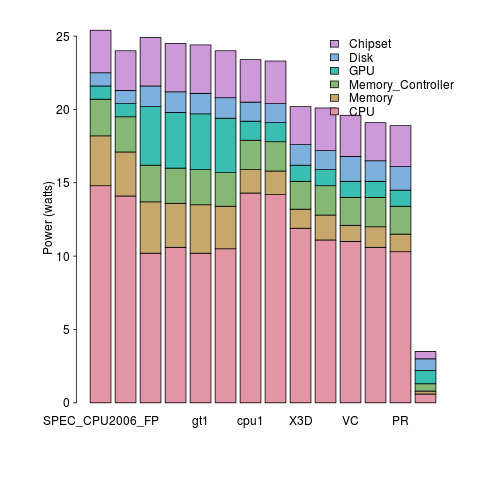
A study by Bircher measured power consumption of various system components, of an Intel server containing four Pentium 4 Xeons, when executing the SPEC CPU2006 benchmark. The power distribution for mobile devices would show the screen being the largest user of power, but I don’t have that data).
A study by Bircher measured memory (blue) and cpu (red) power consumption, in watts, executing the SPEC CPU2006 benchmarks. No point optimizig cpu power if over half the total power is consumed by memory.
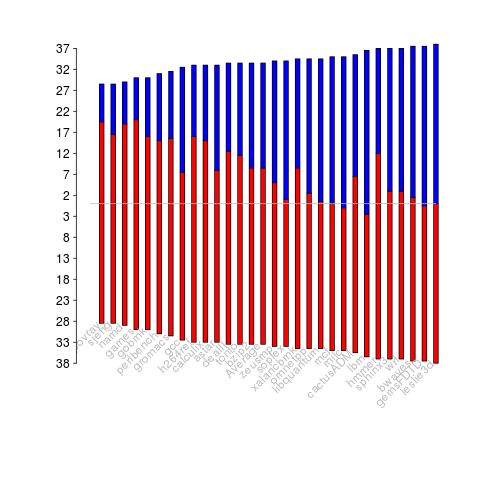
A study by Krevat, Tucek and Ganger measured the performance of then modern disk drives originally sold in 2002 (left) and 2006 (right). Different colors showing through on the right indicates that some discs have different performance characteristics than the others (faster performance -> less time -> less power, i.e., I don’t have power data for disk differences)
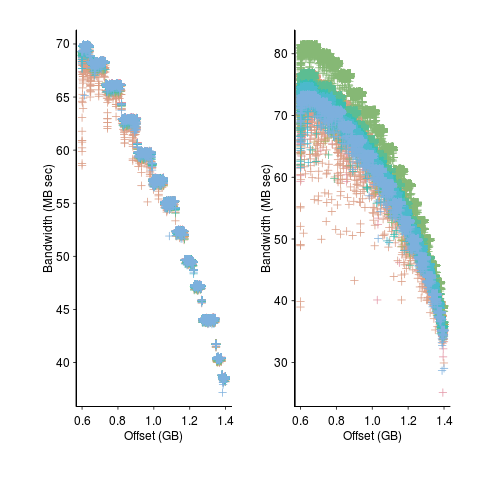
A study by Kalibera et al executed a benchmark 2,048 times followed by system reboot, repeated 10 times. Performance is consistent within a particular reboot, but not across them.

The following plot is in the slide deck and is included here as a teaser (i.e., more later). It shows data for 2,386 processors (x-axis is slowdown, y-axis clock frequency, top right legends max power), which thanks to Barry is now publicly available (or at least will be once some web details are sorted out).
Long tail licensing
Team ‘Long Tail Licensing’ (Richard, Pavel, Gary and yours truly) took part in the Fintech startupbootcamp hackathon at the weekend.
As the team name suggests the plan was to implement a system of payment and licensing for products in the long tail, i.e., a large number of low value products. Paypal is good for long tail payment but does not provide a way for third parties to verify that a transaction has occurred (in fact Paypal does its best to keep transactions secret from everybody except those directly involved).
Our example use case was licensing of individual Github repositories. Most of today’s 3.4 million developers with accounts on Github would rather add more features to their code than try to sell it; the 16.7 million repositories definitely qualifies as a long tail of low value products (i.e., under £100). Yes, Paypal could be (and is) used as a method of obtaining payment, but there is no friction-free method for handling licensing (e.g., providing proof of licensing to third parties).
Long Tail Licensing’s implementation used cryptocurrency for both payment and proof of licensing (by storing license information in the blockchain). For the hackathon we set up out own private Bitcoin blockchain to act as a test rig, supply fast mining and provide near instantaneous response.
To use Long Term Licensing a developer creates the file .cryptolicense in the top level directory of their repo; this file contain information on the amount to pay, cryptocurrency account details and text of licensing terms. A link in the README.md file points at our server, which validates the .cryptocurrency file and sets up a payment transaction from the licensee’s Bitcoin wallet; the licensee confirms the transaction and the payment is made.
The developer’s chosen license information is included in the transactions blockchain, providing the paperwork that third-parties can view to verify what has been licensed. This licensing information could be in plain text or use public key encryption to restrict who can read it (e.g., eBay could publish a public key that third parties could encrypt information so that only eBay’s compliance department could read it).
The implementation code includes links to private servers and other stuff that it should not be be; hackathon code is rarely written with security in mind. So those involved would rather it not be pushed to Github (perhaps it will get tidied up and made suitable for public consumption at a later date).
We did not win any of the prizes :-(. Well done to Manoj (a frequent hackathon collaborator) and his team for winning the $100k of Google cloud time prize.
Do languages evolve to minimise portability?
Governments promote standards because following them helps their citizens save money. The UK and US have contrasting positions, with the UK focusing on savings achieved through the repeated use of standardized items and the US focusing on the repeated use of skills people acquired through using a standardized item.
What benefit, if any, do product vendors receive from adhering to a standard? A few vendors may be in a position to use economies of scale to gain market share (by driving out of business less well funded competitors), other vendors follow a specified standard as a means of winning a contract with large customers, and the rest don’t care.
In the program language world, for 20 odd years, there were just the Cobol and Fortran standards. These started out idealistically driven because hardware vendors had to convince potential customers that it was commercially viable for them to write software for the products they were selling (i.e., the early computers). Once business started to take off, the computer industry’s compete/cooperate dynamic, mixed with large egos wanting their own way and the sales driven mandate to keep existing customers happy (i.e., don’t break existing code) took over. There was lots of infighting and progress was slow, but at least there were lots of people who thought it important enough to be involved.
In the mid-1980s there was a seismic shift in approach to language standards with Pascal and C becoming ISO standards, the first created by a group of mainly academics and the second by a group containing many small company consultants/vendors. The age of ‘activist’ language ISO standard creation had begun; which is not to say that anything changed in the Cobol and Fortran standards’ world. For a look back at this decade see: Computer Standards & Interfaces, volume 16, numbers 5 & 6, Sep 1994.
If you were to put somebody who knew nothing about computer languages in a room with the standard’s committees for Modula-2 and C++, I don’t think they would be able to tell them apart. Inside the bubble, it’s not possible to distinguish the language that died before its standard was published and the language that continues to grow like Topsy.
Activists want to get things done and will select the route of minimal bureaucratic resistance. These days this means that new language standards are often created locally and fed into the ISO process higher once they are done.
Open source compilers have solved many of the source portability problems caused by language dialects, that standards were intended to solve, by dramatically shrinking the market of the compilers that supported those dialects.
Where has the user been in all this? Well, where-ever they are, they are rarely seen at language standard meetings.
These days, portability problems are caused by the multitude of languages, not by the multitude of dialects of a language.
Recent Comments