Archive
My no loops in R hair shirt
Being professionally involved with analyzing source code, I get to work with a much larger number of programming languages than most people. There is a huge difference between knowing the intricate details of the semantics of a language and being able to fluently program in a language like a native developer. There are languages whose semantics I probably know better than nearly all its users and yet can only code in like a novice, and there are languages whose reference manual I might have read once and yet can write fluently.
I try not to learn new languages in which to write programs, they just clutter my brain. It can be very embarrassing having somebody sitting next to me while I write an example and not be able to remember whether the language I am using requires a then in its if-statement or getting the details of a print statement wrong; I am supposed to be a computer language expert.
Having decided to migrate from being a casual R user to being a native user (my current status is somebody who owns more than 10 books that make extensive use of R) I resolved to invest the extra time needed to learn how to write code the ‘R-way’ (eighteen months later I’m not sure that there is an ‘R way’ in the sense that could be said to exist in other languages, or if there is it is rather diffuse). One of my self-appointed R-way rules is that any operation involving every element of a vector should be performed using whole vector operations (i.e., no looping constructs).
Today I was analyzing the release history of the Linux kernel and wanted to get the list of release dates for the current version of the major branch; I had a list of dates for every release. The problem is that when a major release branch is started previous branches, now in support only mode, may continue to be maintained for some time, for instance after the version 2.3 branch was created the version 2.2 branch continued to have releases made for it for another five years.
The obvious solution to removing non-applicable versions from the release list is to sort on release date and then loop through the elements, removing those whose version number was less than the version appearing before them in the list. In the following excerpt the release of 2.3.0 causes the following 2.2.9 release to be removed from the list, also versions 2.0.37 and 2.2.10 should be removed.
Version Release_date 2.2.8 1999-05-11 2.3.0 1999-05-11 2.2.9 1999-05-13 2.3.1 1999-05-14 2.3.2 1999-05-15 2.3.3 1999-05-17 2.3.4 1999-06-01 2.3.5 1999-06-02 2.3.6 1999-06-10 2.0.37 1999-06-14 2.2.10 1999-06-14 2.3.7 1999-06-21 2.3.8 1999-06-22 |
While this is an easy problem to solve using a loop, what is the R-way of solving it (use the xyz package would be the answer half said in jest)? My R-way rule did not allow loops, so a-head scratching I did go. On the assumption that the current branch version dates would be intermingled with releases of previous branches I decided to use simple pair-wise comparison (which could be coded up as a whole vector operation); if an element contained a version number that was less than the element before it, then it was removed.
Here is the code (treat step parameter was introduced later as part of the second phase tidy up; data here):
ld=read.csv("/usr1/rbook/examples/regression/Linux-days.csv") ld$Release_date=as.POSIXct(ld$Release_date, format="%d-%b-%Y") ld.ordered=ld[order(ld$Release_date), ] strip.support.v=function(version.date, step) { # Strip off the least significant value of the Version id v = substr(version.date$Version, 1, 3) # Build a vector of TRUE/FALSE indicating ordering of element pairs q = c(rep(TRUE, step), v[1:(length(v)-step)] <= v[(1+step):length(v)]) # Only return TRUE entries return (version.date[q, ]) } h1=strip.support.v(ld.ordered, 1) |
This pair-wise approach only partially handles the following sequence (2.2.10 is greater than 2.0.37 and so would not be removed).
2.3.6 1999-06-10 2.0.37 1999-06-14 2.2.10 1999-06-14 2.3.7 1999-06-21 |
The no loops rule prevented me iterating over calls to strip.support.v until there were no more changes.
Would a native R speaker assume there would not be many extraneous Version/Release_date pairs and be willing to regard their presence as a minor data pollution problem? If so, I have some way to go before I might be able to behave as a native.
My next line of reasoning was that any contiguous sequence of non-applicable version numbers would probably be a remote island in a sea of applicable values. Instead of comparing an element against its immediate predecessor, it should be compared against an element step back (I chose a value of 5).
h2=strip.support.v(h1, 5) |
The original vector contained 832 rows, which was reduced to 745 and then down to 734 on the second step.
Are there any non-loop solutions that are capable of handling a higher density of non-applicable values? Do tell if you can think of one.
Update (a couple of days later)
Thanks to Charles Lowe, Wojtek and kaz_yos for their solutions using cummax, a function that I was previously unaware of. This was a useful reminder that what other languages do in the syntax/semantics R surprisingly often does via a function call (I’m still getting my head around the fact that a switch-statement is implemented via a function in R); as a wannabe native R speaker I need to remove my overly blinked language approach to problems and learn a lot more about the functions that come as part of the base system
Success does not require understanding
I took part in the second Data Science London Hackathon last weekend (also my second hackathon) and it was a very different experience compared to the first hackathon. Once again Carlos and his team really looked after us.
- The data was released 24 hours before the competition started and even though I had spent less than half an hour looking at it, at the start of the competition I did not feel under any time pressure; those 24 hours allowed me to get used to the data and come up with some useful looking ideas.
- The instructions for the first competition had suggested that people form teams of 3-5 and there was a lot of networking happening before the start time. There was no such suggestion this time and as I networked around looking for people to work with I was surprised by the number of people who wanted to work alone; Jonny and Kannappan were the only members from my previous team (the Outliers) who had entered this event, with Kannappan wanting to work alone and Jonny joining me to create a two person team.
- There was less community spirit this time, possible reasons include a lot more single person teams sitting in the corner doing their own thing, fewer people attending (it is the middle of the holiday season), fewer people staying over until the Sunday (perhaps single person teams got disheartened and left or the extra 24 hours of data access meant that teams ran out of ideas/commitment after 36 hours) or me being reduced to a single person team (Jonny had to leave at 20:00) meant I paid more attention to what was happening on the floor.
The problem was to predict what ratings different people would give to various music artists. We were given data involving 50 artists and 48,645 users (artists and users were anonymous) in five files (one contained the training dataset and another the test dataset).
A quick analysis of the data showed that while there were several thousand rows of data per artist there were only half a dozen rows per person, a very sparse dataset.
The most frequent technique I heard mentioned during my initial conversations with attendees was machine learning. In my line of work I am constantly trying to understand what is going on (the purpose of this understanding is to control and make things better) and consider anybody who uses machine learning as being clueless, dim witted or just plain lazy; the problem with machine learning is that it gives answers without explanations (ok decision trees do provide some insights). This insistence on understanding turned out to be my major mistake, the competition metric is based on correctness of answers and not on how well a competitor understands the problem domain. I had a brief conversation with a senior executive from EMI (who supplied the dataset and provided some of the sponsorship money) who showed up on Sunday morning and he had no problem with machine learning providing answers and not explanations.
Having been overly ambitious last time team Outliers went for extreme simplicity and started out with the linear model glm(Rating ~ AGE + GENDER...) being built for each artist (i.e., 50 models). For a small amount of work we got a score of just over 21 and a place of around 70th on the leader board, now we just needed to include information along the lines of “people who like Artist X also like Artist Y”. Unfortunately the only other member of my team (who did not share my view of machine learning and knew something about it) had a prior appointment and had to leave me consuming lots of cpu time on a wild goose chase that required me to have understanding.
The advantages of being in a team include getting feedback from other members (e.g., why are you wasting your time doing that, look how much better this approach is) and having access to different skill sets (e.g., knowing what magic pixie dust values to use for the optional parameters to machine learning routines). It was Sunday morning before I abandoned the ‘understanding’ approach and started thrashing around using various machine learning techniques, which told me that people demographics (e.g., age and gender) were not particularly good predictors compared to other data but did did not reduce my score to the 13-14 range that could be seen on the leader board’s top 20.
Realizing that seven hours was not enough time to learn how to drive R’s machine learning packages well enough to get me into the top ten, I switched tack and spent a lot more time wandering around chatting to people; those whose score was worse than mine were generally willing to chat. Some had gotten completely bogged down in data cleaning and figuring out how to handle missing data (a subject rarely covered in books but of huge importance in real life), I was surprised to find one team doing most of their coding in SQL (my suggestion to only consider Age+Gender improved their score from 35 to 22), I mocked the people using Clojure (people using a Lisp derived language think they have discovered the one true way and will suffer from self doubt if they are not mocked regularly). Afterwards it struck me that well over 50% of attendees were not British (based on their accents), was this yet another indicator of how far British Universities had dumbed down mathematics teaching that natives did not feel up to the challenge (well done to the Bristol undergraduate who turned up) or were the most gung-ho technical folk in London those who had traveled here to work from abroad?
The London winner was Dell Zhang, the only other person sitting at the table I was on (he sat opposite me throughout the competition), who worked quietly away for the whole 24 hours and seemed permanently unimpressed by the score he was achieving; he described his technique as “brute force random forest using Python (the source will be made available on the Data Science website).
Reading through posts made by competitors after the event was as interesting as last time. Factorization Machines seems to be the hot new technique for making predictions based on very sparse data and the libFM is the software I needed to know about last weekend (no R package providing an interface to this C++ code available yet).
Why does Coverity restrict who can see its tool output?
Coverity generate a lot of publicity from their contract (started under a contract with the US Department of Homeland Security, don’t know if things have changed) to scan large quantities of open source software with their static analysis tools and a while back I decided to have a look at the warning messages they produce. I was surprised to find that access to the output required singing a non-disclosure agreement, this has subsequently been changed to agreeing to a click-through license for the basic features and signing a NDA for access to advanced features. Were Coverity limiting access because they did not want competitors learning about new suspicious constructs to flag, or because they did not want potential customers seeing what a poor job their tool did?
The claim that access “… for most projects is permitted only to members of the scanned project, partially in order to ensure that potential security issues may be resolved before the public sees them.” does not really hold much water. Anybody interested in finding security problems in code could probably find hacked versions of various commercial static analysis tools to download. The SAMATE – Software Assurance Metrics And Tool Evaluation project runs yearly evaluations of static analysis tools and makes the results publicly available.
A recent blog post by Andy Chou, Coverity’s CTO, added weight to the argument that their Scan tool is rather run-of-the-mill. The post discussed a new check that had recently been added flagging occurrences of memcmp, and related standard library functions, that were being tested for equality (or inequality) with specific integer constants (these functions are defined to return a negative or positive value or 0, and while many implementations always return the negative value -1 and the positive value 1 a developer should always test for the property of being negative/positive and not specific values that have that property). Standards define library functions to have a wide variety of different properties, and tools that check for correct application of these properties have been available for over 15 years.
My experience of developer response, when told that some library function is required to return a negative value and some implementation might not return -1, is that they regard any implementation not returning -1 as being ‘faulty’ since all implementations in their experience return -1. I imagine that library implementors are aware of this expectation and try to meet it. However, optimizing compilers often try to automatically inline calls to memcpy and related copy/compare functions and will want to take advantage of the freedom to return any negative/positive value if it means not having to perform a branch test (a big performance killer on most modern processors).
Undefined behavior can travel back in time
The committee that produced the C Standard tried to keep things simple and sometimes made very short general statements that relied on compiler writers interpreting them in a ‘reasonable’ way. One example of this reliance on ‘reasonable’ behavior is the definition of undefined behavior; “… erroneous program construct or of erroneous data, for which this International Standard imposes no requirements”. The wording in the Standard permits a compiler to process the following program:
int main(int argc, char **argv) { // lots of code that prints out useful information 1 / 0; // divide by zero, undefined behavior } |
to produce an executable that prints out “yah boo sucks”. Such behavior would probably be surprising to the developer who expected the code printing the useful information to be executed before the divide by zero was encountered. The phrase quality of implementation is heard a lot in committee discussions of this kind of topic, but this phrase does not appear in any official document.
A modern compiler is essentially a sophisticated domain specific data miner that happens to produce machine code as output and compiler writers are constantly looking for ways to use the information extracted to minimise the code they generate (minimal number of instructions or minimal amount of runtime). The following code is from the Linux kernel and its authors were surprised to find that the “division by zero” messages did not appear when arg2 was 0, in fact the entire if-statement did not appear in the generated code; based on my earlier example you can probably guess what the compiler has done:
if (arg2 == 0) ereport(ERROR, (errcode(ERRCODE_DIVISION_BY_ZERO), errmsg("division by zero"))); /* No overflow is possible */ PG_RETURN_INT32((int32)arg1 / arg2); |
Yes, it figured out that when arg2 == 0 the divide in the call to PG_RETURN_INT32 results in undefined behavior and took the decision that the actual undefined behavior in this instance would not include making the call to ereport which in turn made the if-statement redundant (smaller+faster code, way to go!)
There is/was a bug in Linux because of this compiler behavior. The finger of blame could be pointed at:
- the developers for not specifying that the function
ereportdoes not return (this would enable the compiler to deduce that there is no undefined behavior because the divide is never execute whenarg2 == 0), - the C Standard committee for not specifying a timeline for undefined behavior, e.g., program behavior does not become undefined until the statement containing the offending construct is encountered during program execution,
- the compiler writers for not being ‘reasonable’.
In the coming years more and more developers are likely to encounter this kind of unexpected behavior in their programs as compilers do more and more data mining and are pushed to improve performance. Other examples of this kind of behavior are given in the paper Undefined Behavior: Who Moved My Code?
What might be done to reduce the economic cost of the fallout from this developer ignorance/standard wording/compiler behavior interaction? Possibilities include:
- developer education: few developers are aware that a statement containing undefined behavior can have an impact on the execution of code that occurs before that statement is executed,
- change the wording in the Standard: for many cases there is no reason why the undefined behavior be allowed to reach back in time to before when the statement executing it is executed; this does not mean that any program output is guaranteed to occur, e.g., the host OS might delete any pending output when a divide by zero exception occurs.
- paying gcc/llvm developers to do front end stuff: nearly all gcc funding is to do code generation work (I don’t know anything about llvm funding) and if the US Department of Homeland security are interested in software security they should fund related front end work in gcc and llvm (e.g., providing developers with information about suspicious usage in the code being compiled; the existing
-Wallis a start).
Ternary radix will have to wait for photonic computers
Computer cpu economics suggest that a ternary radix representation rather than binary should be used for representing integer values. The economic cost of a cpu is is roughly proportional to  , where
, where  is the integer radix and
is the integer radix and  is the width, in bits, of the basic integer type (for simplicity I’m assuming there is only one and that the bus width has the same value); the maximum value that can be represented is
is the width, in bits, of the basic integer type (for simplicity I’m assuming there is only one and that the bus width has the same value); the maximum value that can be represented is  .
.
If we fix the maximum representable value  and ask which value of minimises , then we need to differentiate
and ask which value of minimises , then we need to differentiate  w.r.t. , giving
w.r.t. , giving ^2})") and this equals 0 when
and this equals 0 when  (the closest integer to
(the closest integer to  is 3).
is 3).
The following plot shows the maximum representable value (right point of horizontal line) that can be achieved for a given ‘cost’ when the radix is 2 and 3.
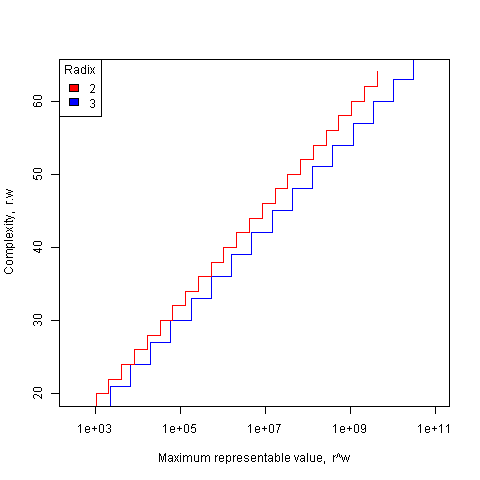
The reason binary is used in practice is purely to do with the characteristics of power consumption in electronic switching circuits (originally vacuum tube and then transistor based). Electrical power is proportional to voltage times current and a binary circuit can be implemented by switching between states where either the voltage or the current is very small, in either of these two states the power consumption is very low; it is only during the very short transition period switching between them, when the voltage and current have intermediate values, that the power consumed is relatively high. A 3-state switch would need a voltage/current combination denoting a state other than 0/1, and any such combination would consume non-trivial amounts of power (tri-state devices are used in some situations).
I have little idea about the complications of storing ternary values in memory systems, but I guess there will be complications.
In the 1960’s the Setun computer used a ternary radix and there has been the odd experimental systems since.
Are there any kinds of switching circuit whose use is not primarily dictated by device power characteristics and hence might be used to support a ternary radix? One possibility is a light based cpu (i.e., using photons rather than electrons), using polarization to specify state has been proposed. What about storage? Using Josephson junctions could provide the high speed and low power consumption required (we just need somebody to discover a room temperature superconductor).
The technology needed to build a practical cpu using a ternary radix appears to be some years in the future.
What about all the existing code containing a myriad of dependencies on the characteristics of two’s complement integer representation? If a photonic cpu became available that was ten times faster than existing cpus, or consumed 10 times less power or some combination thereof, then I’m sure here would be plenty of economic incentive to get software running on it. The problem is that 10 times better cpus are unlikely to just turn up, they will probably need to be developed in steps and the economics of progressing from step to step don’t look good.
While our civilization is likely to continue on down the binary rabbit hole, another one may have started down, or switched to, the ternary hole. I hope the SETI people are not to blinkered by the binary view of the universe.
Recent Comments