Archive
Frequency of floating literals in a given range
Last month I talked about one idea for estimating the ‘interestingness’ of a floating-point literal, counting the number of digits it contains. Another idea is to use the magnitude of the literal’s value; many values seem to cluster in the range -1 to +3 and perhaps a match against a value in this range ought to be filtered in some way.
Assume the two values 1.2 and 1200.0 are in the interesting number database. Both contain the same number of non-zero digits. More matches are likely to occur against the value 1.2, but this does not mean its false positive rate is higher compared to the value 1200 (that information can only come from knowledge of the application domain of the files whose contents are being matched).
Filtering based on the magnitude of a value might be used to reduce the total number of matches reported, e.g., only report the first match of a literal having a value within a certain range.
How often do floating-point literal values occur in source code? The following is based on 4.47 million non-zero floating-point literals (i.e., any literal having value 0.0 was not counted) in a wide variety of numeric source code:
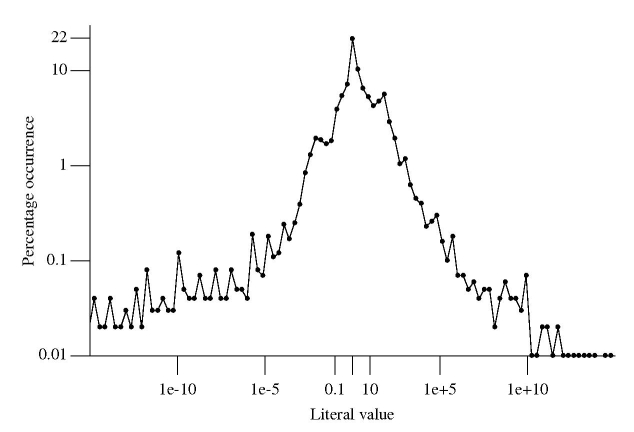
The literal values were put into bins whose width were based on powers of 2. For instance, values between 0.25 and 0.5 went into bin -1, between 0.5 and 0 into bin 0, between 0 and 1 when into bin 1 and so on for smaller and larger numbers.
At 21.6% literals between 0.5 and 0.0 were the most common range, followed at 10.4% for literals between 0.0 and 1.0. The plot is slightly skewed towards having more values greater than 1.
Two discontinuities occur in the value frequencies between 0.001-0.02 and 16-64 (with the smaller values occupying a slightly larger range). This unexpected behavior has been added to my list of things to investigate at some point.
Building directly from a .tgz file
Working on lots of different code bases means I am forever having to extract the contents of tar/zip files before compiling/analysing the files in the extracted directory tree, then deleting the directory tree when I am done. It is about time development tools such as make and compilers had the ability to build directly from an archive.
Vi (well actually Vim and other editors) supports the editing of files contained within an archive and thanks to libarchive the latest version of Numbers also has this functionality.
This is not about saving disc space, it is a way of working that creates a barrier between files created elsewhere and files created by me; it would make it harder for me to accidentally leave my work files in the directory I happened to be sitting, in the directory tree, when working on the source.
There are some design issues that need to be sorted out if build configuration via .configure files is to work correctly. I leave these design issues to the people who know about configuration management.
We will need to extend the existing directory-path/file syntax to support the specification of a file contained within an archive. How about using ::tgz:: as a file prefix to indicate that the subsequent directory/file specification is to be interpreted as referring to the contents of an archive file, e.g.,
cc /home/stuff/::tgz::app.tgz/src/foo/bar.c
I don’t think a separate prefix is needed for each kind of archive, any character sequence that is sufficiently unused at the moment will do.
Go readers, spread the word!
Recent Comments