Archive
Predictions for 2009
If the shape of code does change over time, it changes very slowly. Styles become more or less popular, but again the time-scale is generally longer than a year. Anyway, here are my predictions for goings on the in the community that shapes code.
1) Functional programming will continue to entrance the young whose idealism will continue to be dashed when they have to deal with the real world. Ok, I started with something obvious that will still be true in 20 years and I promise not to to to keep repeating myself on this one every year.
2) The LLVM project will die. I am surprised that it has lasted this long, but it is probably costing Apple so little that it is not on management’s radar. Who needs another C compiler; perhaps 10 years ago they could have given the moribund gcc project a run for its money, but an infusion of keen people and a complete reworking of its internals has kept gcc as the leading contender to be the only C compiler developers use in 10 years time.
3) Static analysis will go mainstream. The driving force will not be developers loosing their aversion to being told of their mistakes, but because the world’s economic predicament will force them to deliver better performance in less time, ie they will be forced to use tools to help them find coding faults. The fact that various groups are starting to add hooks to the mainstream compilers (e.g., Microsoft’s Phoenix, gcc’s Dehydra), ensuring compatibility with an existing code base and making it easier for developers use, also helps. The gcc people may yet shoot themselves in the foot. Of course people will continue to develop new stand-alone tools and extract money from government to do something that sounds useful.
4) Natural language programming will finally gain a foothold. One of the big unnoticed announcements of the year was the Attempto project releasing the source code of their controlled English system.
5) The rate of gcc’s progress to world domination will accelerate. There are still quite a few market niches where gcc is a minority player (eg, embedded systems) and various compilers need to disappear for it to gain market share. Compiler writing has never been a very profitable business and compiler companies usually go bust or are taken over by hardware vendors looking for customer lock-in. The current economic situation means that compiler companies are both more likely to go bust and to not be brought, ie, their compilers will (commercially) disappear.
6) The number of people involved in writing software will continue to decline in the West and increase in the East. These days there is not a lot of difference in cost between east/west, it is the quality of developers (or rather there are more of a reasonable standard available). The declining standards in science/engineering education is the driving factor, the economic situation is just creating extra exposure.
Recommendations for teachers of programming
The software developers I deal with usually have at least 3 or more years professional experience in industry (I have not taught a beginners programming class in over 25 years) and these recommendations are based on what I tell these people. I like to think that they are applicable to teaching those with a lot less experience.
First. Application domain expertise generally has greater value than programming expertise. That is, an investment of time in learning the application domain will yield a greater return on investment that learning more programming techniques.
Implications:
Second. Computer time is cheap, people time is expensive.
Implications:
Third. Most software is written to solve an immediate problem, used a few times, and then forgotten about (I know of software projects costing in the millions where the code was never used; my own contribution to never used code is somewhat smaller, but still much larger than I would have liked). The point is that writing software involves a cost/benefit trade-off, how much should I invest in making code maintainable given the risk that the benefits from this investment may not be recouped.
Implications:
Fourth. Don’t fool yourself that you are teaching programming; you probably just give a lecture or two and expect students to pick up the details from one of the assigned course books.
Implications:
Fifth. Coding style does exist and can have an effect on the cost of writing and maintaining code as well as how well a compiler can optimize it. These costs and benefits vary with the context in which the code was created and used. A good programmer will adopt a coding style appropriate to the context, just like an actor plays a role with the appropriate characterization (eg, comedy, thriller, suspense). It takes more experience than most undergraduate have to be able to properly discern what style is being used, let alone be capable of changing their own style.
Implications:
Searching code for a specific kind of calculation
I am currently involved in a project that requires locating the line(s) of code in a program that calculate(s) the value 3n+1 (and various other constructs associated with coding the 3n+1 problem). Since there are over 4,000 independently written programs, each containing this calculation, the search effort is non-trivial. The obvious solution is to use grep to search for the expression 3*n+1 (the actual regular expression is a bit more complicated since any whitespace needs to be handled and the identifier n might have a different spelling).
This obvious solution works around 80% of the time (based on my manual analysis of the programs; searching for n*3+1 catches another 10%). For many of the authors of these 4,000+ programs simplicity does not seem to be an overriding goal and various alternative forms of the calculation are used (e.g., n+n+n or (n<<2)+n+1 or n+= (n<<2); n++ or even n+=n+++n). It looks like some authors have been unduly concerned with program performance.
The reason I am doing a manual search is that this problem is way beyond the capabilities of existing code search tools. Existing tools all require that the search pattern be specified in terms that are essential lexical. This would not be too much of a problem if I had a means of automatically enumerating a reasonable subset of the expressions that evaluate to 3n+1. (The problem of optimizing the sequence of operations needed to multiply a variable by a constant is a well known issue in compiler code generation and very good algorithms are known (papers+code and matrix multiplication)).
The existing abstract interpretation tools target complete programs, or at least complete functions, and aim to show that certain conditions are met and/or not violated. An abstract interpretation version of grep sounds like an interesting PhD.
After several thousand searches even the most obtuse methods rarely take me more than a few seconds to spot. I can also be easily ‘reprogrammed’ to search just as effectively for other code sequences having some simple result.
Contemplating the major problems that need to be solved before an automatic tool could perform a similar task I am starting to appreciate, once again, the vast gulf that exists between human and computer analysis of code.
Criteria for knowing a language
What does it mean for somebody to claim to know a computer language? In the commercial world it means the person is claiming to be capable of fluently (i.e., only using knowledge contained in their head and without having to unduly ponder) reading, and writing code in some generally accepted style applicable to that language. The academic world generally sets a much lower standard of competence (perhaps because most of its inhabitants leave before any significant expertise is acquired). If I had a penny for every recent graduate who claimed to know a language and was incapable of writing a program that read in a list of integers and printed their sum (I know companies that set tougher problems, but they do not seem to have higher failure rates), I would be a rich man.
One experiment asked 21 postgraduate and academic staff which of the following individuals they would regard as knowing Java:
The results were:
_ NO YES
A 21 0
B 18 3
C 16 5
D 8 13
E 0 21
These answers reflect the environment from which the subjects were drawn. When I wrote compilers for a living, I did not consider that anybody knew a language unless they had written a compiler for it, a point of view echoed by other compiler writers I knew.
I’m not sure that commercial developers would be happy with answer (E), in fact they could probably expand (E) into five separate questions that tested the degree to which a person was able to combine various elements of the language to create a meaningful whole. In the commercial world, stage (E) is where people are expected to start.
The criteria used to decide whether somebody knows a language depends on which group of people you talk to; academics, professional developers and compiler writers each have their own in-group standards. In a sense the question is irrelevant, a small amount of language knowledge applied well can be used to do a reasonable job of creating a program for most applications.
Why is code so fault tolerant?
All professional developers eventually encounter a program containing a fault that appears to be so devastating that the program could not possibly perform its intended task, yet the program has been and continues to function more or less as expected. In my case the program was a cpu instruction set emulator (for a Z80 written in Fortran) that I had written and the fault was a copy-and-past editing mistake that resulted in one of the subtract instructions behaving like the equivalent addition instruction. The emulator was used to execute CP/M and various applications (on a minicomputer that did not have any desktop office applications). I was astounded that CP/M booted and appeared to work correctly, along with various applications (apart from the one exhibiting behavior differences that resulted in me tracking down this fault).
My own continuing experience with apparently fatal faults, in mine and other peoples code, lead me to the conclusion that researchers should be putting most of their effort into trying to figure out why so much software does such a good job of behaving in an acceptable manner while containing so many faults (of various apparent seriousness). Proving software correctness is an expensive and time consuming dead-end for all but a few specialist applications.
One way for developers to vividly see how robust most software is to random faults is to use a mutation tool on the source. Such tools introduce faults into code with the aim of checking the thoroughness of a set of test cases. It is a sobering experience to see how many mutations fail to have any noticeable effect on a programs external behavior.
One group of researchers took this mutation idea to an extreme by changing all less-than operators in for-loops into less-than-or-equals operators. They found that only a handful of the changes prevented the recompiled programs being at all useful to users. While some of the changes produced output that was obviously incorrect, it was still possible to use much of the original functionality.
What is it about the shape of most code that allows it to continue to function in the presence of faults? It is time faults were acknowledged as a fact of life in all actively developed systems and that we should concentrate on developing techniques to help ensure that software containing them continues to behave as intended, rather than the unsophisticated zero-tolerance approach that has held sway for so long.
Parsing without a symbol table
When processing C/C++ source for the first time through a compiler or static analysis tool there are invariably errors caused by missing header files (often because the search path has not been set) or incorrectly defined, or not defined, macro names. One solution to this configuration problem is to be able to process source without handling preprocessing directives (e.g., skipping them, such as not reading the contents of header files or working out which arm of a conditional directive is applicable). Developers can do it, why not machines?
A few years ago GLR support was added to Bison, enabling it to process ambiguous grammars, and I decided to create a C parser that simply skipped all preprocessing directives. I knew that at least one reasonably common usage would generate a syntax error:
func_call(a, #if SOME_FLAG b_1); #else b_2); #endif |
c);
and wanted to minimize its consequences (i.e., cascading syntax errors to the end of the file). The solution chosen was to parse the source a single statement or declaration at a time, so any syntax error would be localized to a single statement or declaration.
Systems for parsing ambiguous grammars work on the basis that while the input may be locally ambiguous, once enough tokens have been seen the number of possible parses will be reduced to one. In C (and even more so in C++) there are some situations where it is impossible to resolve which of several possible parses apply without declaration information on one or more of the identifiers involved (a traditional parser would maintain a symbol table where this information could be obtained when needed). For instance, x * y; could be a declaration of the identifier y to have type x or an expression statement that multiplies x and y. My parser did not have a symbol table and even if it did the lack of header file processing meant that its contents would only contain a partial set of the declared identifiers. The ambiguity resolution strategy I adopted was to pick the most likely case, which in the example is the declaration parse.
Other constructs where the common case (chosen by me and I have yet to get around to actually verifying via measurement) was used to resolve an ambiguity deadlock included:
f(p); // Very common, // confidently picked function call as the common case (m)*p; // Not rare, // confidently picked multiplication as the common case (s) - t; // Quiet rare, // picked binary operator as the common case (r) + (s) - t; // Very rare, //an iteration on the case above |
At the moment I am using the parser to measure language usage, so less than 100% correctness can be tolerated. Some of the constructs that cause a syntax error to be generated every few hundred statement/declarations include:
offsetof(struct tag, field_name) // Declarators cannot be //function arguments int f(p, q) int p; // Tries to reduce this as a declaration without handling char q; // it as part of an old style function definition { MACRO(+); // Preprocessing expands to something meaningful |
Some of these can be handled by extensions to the grammar, while others could be handled by an error recovery mechanism that recognized likely macro usage and inserted something appropriate (e.g., a dummy expression in the MACRO(x) case).
Distribution of numeric values (additive)
Developers and testers rarely put any thought into working out the likely distribution of numeric values (final or intermediate) computed during the execution of the code they write.
The likely value of a variable is useful to know in a number of situations, including optimizing code (should it prove to be necessary) for the common case and testing (what distribution of input values are needed to be confident that all paths through a program are exercised?)
The answer for the ‘simple’ distributions is actually more complicated to work with than the more ‘complicated’ distributions. For instance, the sum of two independent values having a normal distributions is a normal distribution and the sum of two Poisson distributions is also a Poisson distribution.
What if the values are uniformly distributed? If two independent, randomly chosen, uniformly distributed, variables, are added what is the distribution of the result? For instance, if the values of X and Y are independent of each other and take on any value between 0 and 9, with equal likelihood, what is the most (and least) likely value of X+Y?
Warning: Information spoilers follow.
You are probably thinking that the result will also be uniformly distributed and indeed it would be if the range of values taken by X and Y did not overlap. When the possible range of values overlap exactly the answer is the triangular distribution, with the mostly likely result being 9 and the least likely results being 0 and 18.
The variance of the actual result distribution is approximately six times smaller than the original distribution, meaning that the common cases occupy a much narrower value range. This value range ‘narrowing’ goes someway towards helping to explain the surprising discovery that during program execution a small set of (integer and floating) values often occur with such regularity that it might be worth cpu arithmetic units remembering previous operands and their results (i.e., to save time by returning the result rather than recalculating it).
Benford’s law and numeric literals in source code
Benford’s law applies to values derived from a surprising number of natural and man-made processes. I was very optimistic that it would also apply to numeric literals in source code. Measurements of C source showed that I was wrong (the chi-square fit was 1,680 for decimal integer literals and 132,398 for floating literals).
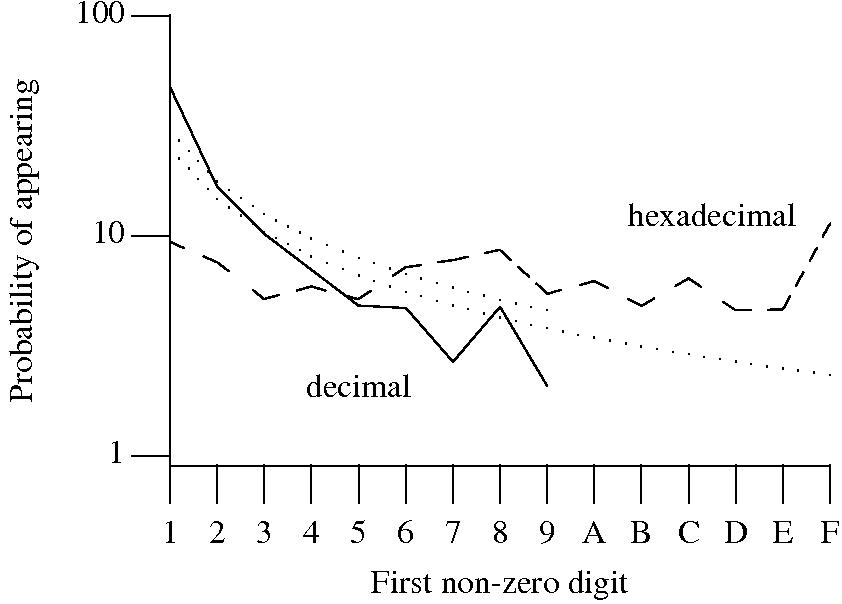
Probability that the leading digit of an (decimal or hexadecimal) integer literal has a particular value (dotted lines predicted by Benford’s law).
What are the conditions necessary for a sample of values to follow Benford’s law? A number of circumstances have been found to result in sample values having a leading digit that follows Benford’s law, including:
Samples that have been found to follow Benford’s law include lists of physical constants and accounting data (so much so that it has been used to detect accounting fraud). However, the number of data-sets containing values whose leading digit follows Benford’s law is not a great as some would make us believe.
Why don’t the leading digits of numeric literals in source code follow Benford’s law?
++/-- operators reduces the number of instances of 1 to increment/decrement a value). But this only applies to integer types, not floating types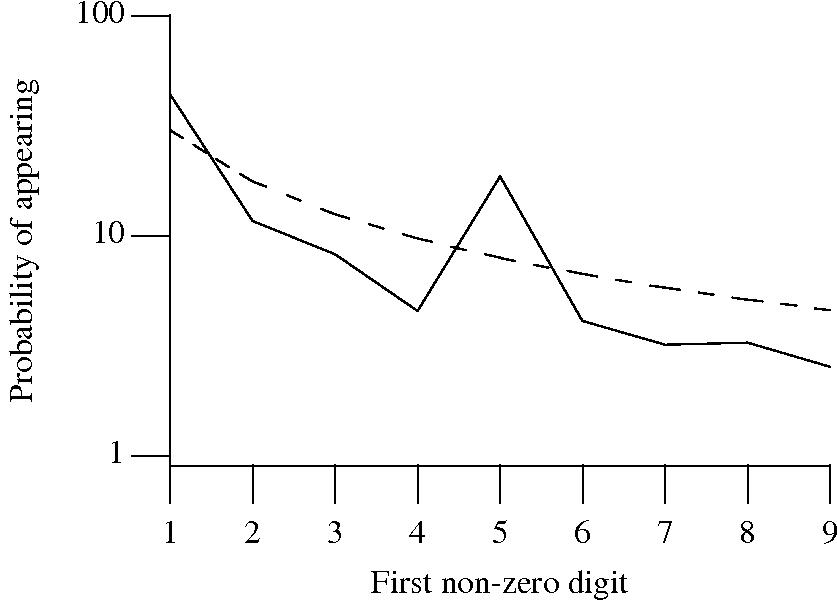
Probability that the leading, first non-zero, digit of a floating literal has a particular value (dashed line predicted by Benford’s law).
5 for the floating-point literals? Have values been rounded to produce 0.5? This looks like an area where methods used for accounting fraud detection might be applied (not that any fraud is implied, just irregularity).These surprising measurements show that there is a lot to the shape of numeric literals that is yet to be discovered.
How widely used is a language?
How widely used is a language? Nobody really knows and since there is nothing anybody can do to control usage (both IBM and the US DOD have tried) the question is probably of only academic interest.
Languages are used in a variety of ways and contexts, and it is possible that while one language currently occupies the greatest number of programmer hours, a different one has the greatest number of lines of code ever written in it, another the greatest number of lines of code currently in existence, and a fourth utilize the most CPU time.
Some languages are very popular for particular kinds of applications or within industries. For example, COBOL is still strong in corporate data centers; Fortran in engineering applications; C in embedded applications and operating systems; C++ and Java for writing desktop applications; Perl, PHP, etc. for web based applications.
There are various methods of measuring language popularity, each subject to a different bias over what is measured, that might be used, including:
- counting the number of job advertisements that mention the language. Money counts, so this may be a solid indicator. However, beware, companies like to paint a rosy picture and sometimes mention languages they don’t use just to attract people to apply for the job.
- measuring the financial value of companies making a living through selling tools for a particular language. As an ex-compiler writer I know that compared to applications software, compilers make very little money (compiler companies invariably go bust or get bought by a hardware vendor looking for leverage). Microfocus is the only (primarily) compiler based company to have grown to a significant size and exist independently for a long period of time
- the number of books sold that teach or describe the language. This will be biased towards the more recently popular languages.
- estimates of the number of existing lines of code written in the language—which will underestimate languages not often found in public searches, e.g., there is very little Cobol source available on the web (is this because the kind of people who write Cobol are not the kind to make it publicly available or are the applications so specialized that web distribution is not considered worthwhile?)
- counts of language references (i.e., to the name of the language) found using a web search engine.
Some of the above material exists in a section of a Wikipedia article I wrote some time ago.
C++ goes for too big to fail
If you believe the Whorfian hypothesis that language effects thought, even in one of its weaker forms, then major changes to a programming language will affect the shape of the code its users write.
I was at the first International C++ Standard meeting in London during 1991 and coming from a C Standard background I could not believe the number of new constructs being invented (the C committee had a stated principle that a construct be supported by at least one implementation before it be considered for inclusion in the standard; ok, this was not always followed to the letter). The C++ committee members continued to design away, putting in a huge amount of effort, and the document was ratified before the end of the century.
The standard is currently undergoing a major revision, and the amount of language design going on puts the original committee to shame. With over 1,300 pages in the latest draft nobodies favorite construct is omitted. The UK C++ panel has over 10 people actively working on producing comments and may produce over 1,000 on the latest draft.
With so many people committed to the approach being taken in the development of the revised C++ Standard its current direction is very unlikely to change. The fact that most ‘real world’ developers only understand a fraction of what is contained in the existing standard has not stopped it being very widely used and generally considered as a ‘success’. What is the big deal over a doubling of the number of pages in a language definition, the majority of developers will continue to use the small subset that they each individually have used for years.
The large number of syntactic ambiguities make it is very difficult to parse C++ (semantic information is required to resolve the ambiguities and the code to do this is an at least an order of magnitude bigger than the lexer+parser). This difficulty is why there are so few source code analysis tools available for C++, compared to C and Java, which are much much easier to parse. The difficulty of producing tools means that researchers rarely analyse C++ code, and only reasonably well funded efforts are capably of producing worthwhile static analysis tools.
Like many of the active committee members, I have mixed feelings about this feature bloat. Yes, it is bad, but it will keep us all actively employed on interesting projects for many years to come. As the current financial crisis has shown, one of the advantages of being big and not understood is that you might get to being too big to fail.
Recent Comments