Two models of developer response to false positive warnings
Static analysis tools sometimes fail to warn about a problem in the source and sometimes generate a warning for perfectly correct code (so called false positives). Experience shows that false positive warnings are very unpopular with developers (they are a source of wasted effort) and if too many false positive warnings are encountered a developer will often stop using the tool; developer’s are more likely to consider a lack of warnings as a positive indicator of the quality of their code than a failure of the tool to detect a problem, of course failure to detect problems may result in a poor evaluation and a lost sale.
What percentage of false positive warnings can a static analysis tool generate before a developer is likely to stop using it?
The following are two possible developer mental models that can be used to help answer this question (it is assumed that there is no correlation between warning occurrences and developers do not differentiate on the type of construct being warned about):
- a ‘rational’ developer who tracks the benefit of processing each warning (e.g., correct warning +1 benefit, false positive warning -1 benefit), starting in an initial state of zero benefit this rational developer stops processing warnings if the current sum of benefits ever goes negative.

The Ballot theorem can be used here. Let
Cbe the number of correct warnings andFbe the number of false positive warnings and assumeC > F. The probability that in a sequential count of warnings the number of correct warnings is always greater than the number of false positive warnings is:
rewriting in terms of probability of the two kinds of warning we get:

so, for instance, the probability of processing all the warning generated by a tool is 0.5 when the false positive rate is 0.25 and does not depend on the total number of warnings that have to be processed.
- a ‘short-termist’ developer who processes each warning and stops when a sequence of
Nconsecutive false positive warnings have been encountered. This kind of thinking is analogous to that of the hot hand in sports (what psychologists call the clustering illusion)
What is the probability that a sequence of
Nconsecutive false positive warnings is not encountered? Feller provides one solution (see equations 12 & 13 on Mathworld) but equation 2 on mathpages is easier to work with and was used to produce the following graph: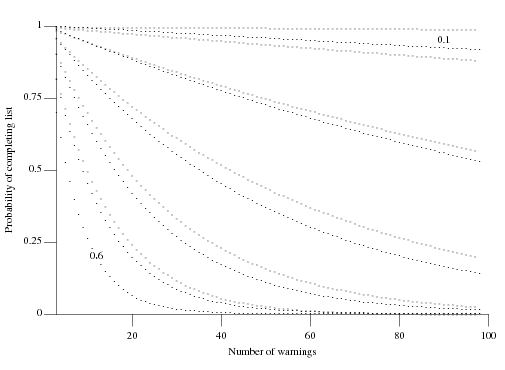
which plots the probability of not encountering a sequence of
Nconsecutive false positive warnings (dotsN=3, crossesN=4) after having processed a given number of warning messages for various underlying rates of false positive (ranging from 0.6 to 0.1 in increments of 0.1).
These models are both based on the false positive rate as judged by the developer, which need not reflect reality. For instance, when dealing with warnings involving complex constructs a developer may be unwilling to put the effort into understanding what is going on and either go along with the what the static analysis tool says, thus underestimating the actual false positive rate, or default to assuming the waring is a false positive, thus overestimating the actual false positive rate.
I have been meaning to write about this topic for a while and an email from Paul Anderson galvanized me into action. Paul’s email involved a slightly different issue “… if the human has seen lots of false positives, there is an increased probability that a true positive will be misjudged as a false positive.”
In some companies developers are required to process each message generated by a tool. Now if a developer looses confidence in a tool it would look suspicious if at some point they simply flagged all subsequent warnings as false positives. What algorithm might such developers use to ‘recalibrate’, e.g., skipping over the next M warnings? This sounds like a problem in foraging theory and a possible topic for a future post.
-
August 2nd, 2010 at 21:53 | #1The Shape of Code » Is unreachable code primarily created by a fault?
Recent Comments